Thanks! But, there will be 100 of reports, will this hash be able to handle that?
@suite ||= {}
@row ||= {}
Thanks! But, there will be 100 of reports, will this hash be able to handle that?
@suite ||= {}
@row ||= {}
If it is only hundreds then the memory leak should not matter. If it is more you would have to re-implement things using an aggregate filter. Use the file name as the task id, and save the row number in the map. Set 'push_map_as_event_on_timeout => true' and in timeout_code call event.cancel so that map entry gets timed out and deleted but does not show up as an event.
Thanks! I'll try that one. 
Hi, what does mean of this comment "# Needs a literal newline in the configuration file" in the conf file?
That mutate+split is splitting the [@metadata][lines] field into an array, and it needs to split them at each newline character. You cannot use "\n", you have to have a literal newline in the string, so that the filter configuration is split across two lines of the file.
ok, thanks!
Hi,
In the csv file, there is a field called Suite/Test/Step Name . Using below code I was trying to rename it in logstash conf file. Renaming worked but in kibana, it says that this new field Test_Step_Name is a undefined field. it doesn't allow to use this new filed to aggregate data. How to fix this?
mutate {
rename => ["Suite/Test/Step Name", "Test_Step_Name" ]
}
What do you mean by that?
Hi @Badger
I meant, in the CSV file there is a column called Suite/Test/Step Name and I wanted to rename that column to a new field name called Test_Step_Name.
I would expect that mutate+rename to achieve that.
Renaming works, but when I check the field in the kibana, it shows that new field as a undefined field. any idea why is that?
Does doing a refresh of the index pattern help? I am not sure what you mean by undefined.
Refreshing didn't work. undefined meant it doesn't have a initial data type. usually for Suite/Test/Step Name it has the data type as text. but for Test_Step_Name it has the data type ? when I check it in kibana. Please check the below screenshot.
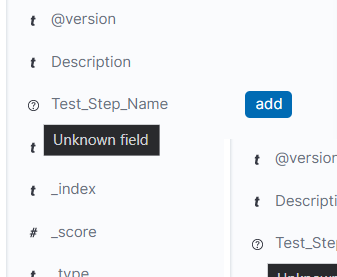
And also @Badger do you know how to change the text color in kibana dashboard widgets. In the below screenshot, there are three different lens widgets in the dashboard. I want to change the text color of Passed count to green and failed count to red. How can I do that in kibana dashboard? (note: I use kibana version 7.8.0)

I would expect refreshing the pattern to fix that. The other question is most definitely a Kibana question and I do not run Kibana, so I cannot help. Try asking in the kibana forum.
OK! thank you for your support so far!
Hi @Badger
In my csv file there is a column which has the katalon test case execution duration; As an example, values are like this "4.23s, 0.02s etc.". End of every value there is a char "s" to denote the seconds. How to remove this and add this particular field to float data type? Currently it saves data as "text" data type.
mutate { gsub => [ "someField", "s$", "" ] }
mutate { convert => { "someField" => "float" } }Hi,
Thank you for your reply. ![]() I have added this,
I have added this,
csv{
separator => ","
skip_header => "true"
columns => ["Suite/Test/Step Name","Browser","Description","Tag","Start time","End time","Duration","Status"]
skip_empty_columns => "false"
convert => {
"Start time" => "date_time"
"End time" => "date_time"
}
}
mutate { gsub => [ "Duration", "s$", "" ] }
mutate { convert => { "Duration" => "float" } }
but outcome is still the same which means duration is still the same as "2.34s".
I am unable to explain that.
© 2020. All Rights Reserved - Elasticsearch
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant logo are trademarks of the Apache Software Foundation in the United States and/or other countries.