Hello,
I search to put aggregat on my data.
Here a party of my data :
TYPE Usage
FREEUSER 345
PREMIUM_USER 8653
FREEUSER 1369
FREEUSER 87654
PREMIUM_USER 43678
FREEUSER 8654
PREMIUM_USER 2387
FREEUSER 98723
FREEUSER 45873
PREMIUM_USER 2847
PREMIUM_USER 89235
USER_UNKNOW 16235
USER_GOLD 32457
My aim is :
To sum Usage by type of client, example :
For user no gold, i want know the sum of usage :
So, USER_PREMIUM & FREEUSER, USER_UNKNOW have use a total of 405 653 octets.
Currentl, in kibana when i test this, i have the sum of usage by type of user 
I thought that in filter of logstash :
if [TYPE] == "FREEUSER or PREMIUMUSER or UNKNOW_USER" {
aggregate {
task_id => "%{taskid}"
code => "map['USAGE'] ||= 0 ; map['USAGE'] += event.get('USAGE_no_gold')"
}
}
What do you think
In general I suggest you perform aggregations in Elasticsearch (typically via Kibana), not Logstash. The Kibana group can give suggestion for how to solve your problem.
I have also see, we can parameter this in Kibana with devtool ?
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "TYPE" : "PREMIUMUSER, FREEUSER, UNKNOW_USER" }
}
}
},
"aggs" : {
"sum_no_gold_user" : { "sum" : { "field" : "USAGE" } }
}
}
Can you explain me the difference between solutions ?
aha Thank you @magnusbaeck i put the question simultaneous
@magnusbaeck Sorry but, you seem a hero of ELK Stack.
What do you think about painless scripted field ? Is deprecated no ?
I find use of DevTool more intuitive.
Here a proposed solution:
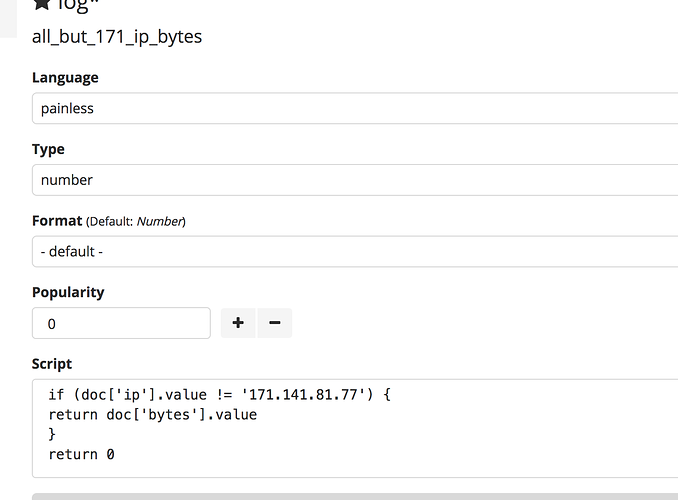
Painless was introduced in ES 5.0 and has not been deprecated.
thank you @magnusbaeck you are amazing.
To close this topic, we must wait 1 month ?
See you soon