Hello,
I'm having a character encoding problem. I have a .ndjson file in UTF-8 encoding. For some reason I can't understand, even though I explicitly specify UTF-8 encoding in the input file, the output contains misinterpreted characters. Here's my logstash configuration:
input {
file {
path => ["/etc/logstash/conf.d/qoreultima/events/events.ndjson"]
start_position => "beginning"
sincedb_path => "/dev/null"
codec => json {
target => "evenement"
charset => "UTF-8"
}
}
}
filter {
mutate {
gsub => [ "[evenement][EventDate]", '(\d{4}-\d{2}-\d{2})T.*', '\1']
remove_field => [ "event", "log" ]
}
date {
match => [ "[evenement][EventDateAndTime]", "yyyy-MM-dd HH:mm:ss" ]
timezone => "America/Montreal"
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ['https://someserver:9200']
data_stream => "true"
data_stream_type => "logs"
data_stream_dataset => "logstash.qoreultima"
user => "user"
password => "password"
ssl_certificate_authorities => ["/some/path/cert.crt"]
ssl_verification_mode => "full"
ecs_compatibility => v8
}
}
Here is a preview of the input file ( :
{"EventID":1,"EventDate":"2023-11-22T00:00:00","EventTime":"08:33:30","EventLoggedBy":"Unknow User","EventAction":"Accès refusé","EventEntityID":null,"EventDescription":"Accès refusé","EventQueries":"Accès refusé","EventLang":"FR","EventIpAddress":null,"EventDateAndTime":"2023-11-22 08:33:30"}
{"EventID":2,"EventDate":"2023-11-22T00:00:00","EventTime":"08:33:30","EventLoggedBy":"Unknow User","EventAction":"Accès refusé","EventEntityID":null,"EventDescription":"Accès refusé","EventQueries":"Accès refusé","EventLang":"FR","EventIpAddress":null,"EventDateAndTime":"2023-11-22 08:33:30"}
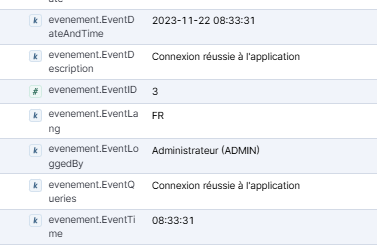
{"EventID":3,"EventDate":"2023-11-22T00:00:00","EventTime":"08:33:31","EventLoggedBy":"Administrateur (ADMIN)","EventAction":"Connexion réussie à l'application","EventEntityID":null,"EventDescription":"Connexion réussie à l'application","EventQueries":"Connexion réussie à l'application","EventLang":"FR","EventIpAddress":null,"EventDateAndTime":"2023-11-22 08:33:31"}
Here’s the output of the command file -bi /some/path/events/events.ndjson on my file :
text/plain; charset=utf-8
When querying in Kibana, Accès refusé become
![]()
The other character (é à …) also have problem to be displayed correctly.
Do someone have an idea of what could be the problem ?
Thanks a lot