I am not an expert on RabbitMQ, but some of the caveats that are called out on the Sharding Plugin's docs are disconcerting:
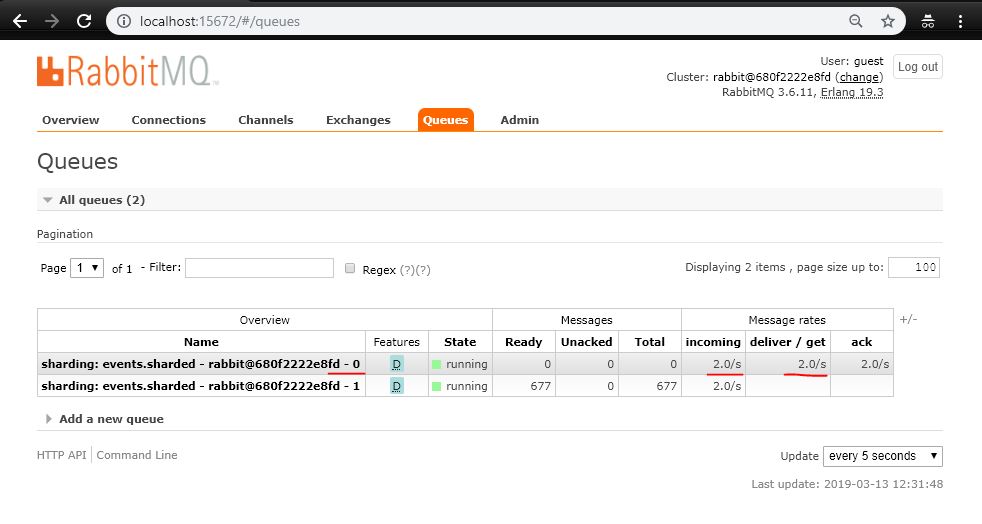
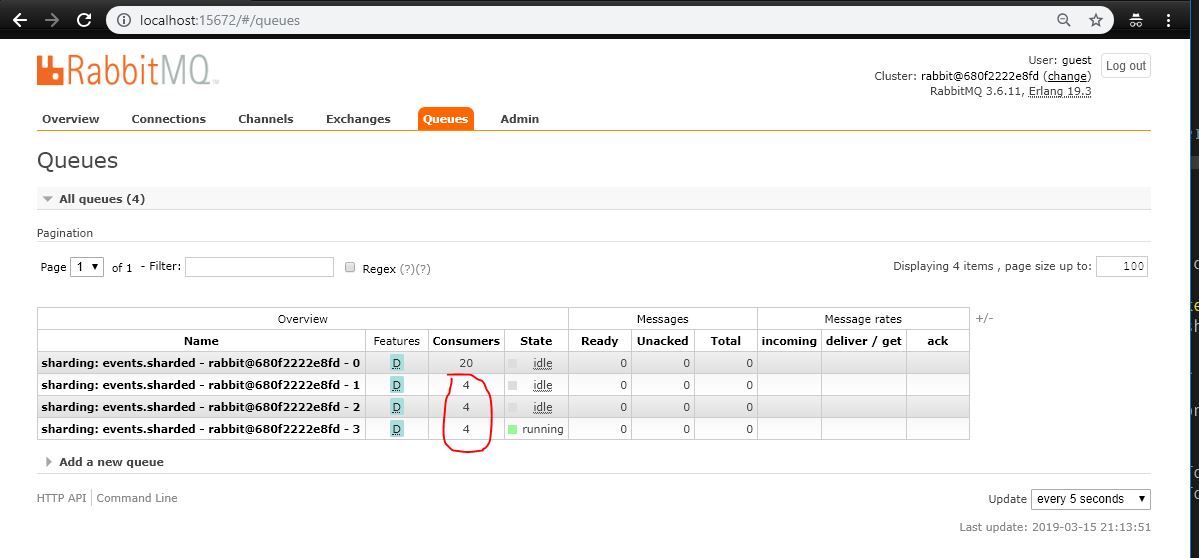
How does it work? The plugin will chose the queue from the shard with the least amount of consumers , provided the queue contents are local to the broker you are connected to.
NOTE: there's a small race condition between RabbitMQ updating the queue's internal stats about consumers and when clients issue basic.consume commands. The problem with this is that if your client issue many basic.consume commands without too much time in between, it might happen that the plugin assigns the consumers to queues in an uneven way.
Again, this plugin is a RabbitMQ-internal thing, that is not supposed to expose itself in any way to consumers. It does not add any options to the APIs that the consumers use to connect. I don't know why it is failing to route consumers, but it is outside of the control of the Logstash RabbitMQ Input.
The caveats in the documentation about the RabbitMQ Sharding plugin indicating that it does not guarantee that consumers will be routed to all queues would be enough for me to not use it in any production environment.
I'm testing this rabbitmq plugin because I need to share the same type of messages between some queues. The idea is to increase the throughput and use more then one CPU for each rabbitmq node.
I did other test, I created rabbitmq's queues manually.
The problem is to setup a logstash pipeline for each queue, I need to specify only one queue name in the input settings.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.