Copy! Got it sir.
I'm getting more lenient to doc_count than the keyword frequency per document
My problem now is with the adjacency_matrix aggs, my keywords are on string data type. Since we're using Laravel (PHP-based framework) MySQL and Sphinx as the legacy database and search server, the keywords stored doesn't have similar patterns so I can't find a way to segregate the main keywords from the negated ones -- the ones in the NOT format of the query_string query (roughly we already have 25,000+ records now.
Going back to the adjacency_matrix aggs, here's my scenario:
I have this string as the user's keyword:
"(("Mayor Isko Moreno" OR "Mayor Vico Sotto") AND ("Manila" OR "Pasig"))"
With my attempt using the significant_text from our earlier replies, I have found a way to explode the string and convert it into an array

Now I have added it to the adjacency_matrix aggs

And the result:

The problem I'm seeing:
What I'm getting at, is that the adjacency_matrix looks like joining all the 4 significant words from my keywords as one -- considering all documents that all 4 of them are appearing, but logically speaking, the keyword is only choosing one from "Mayor Isko Moreno" OR "Mayor Vico Sotto" AND "Manila" OR "Pasig"
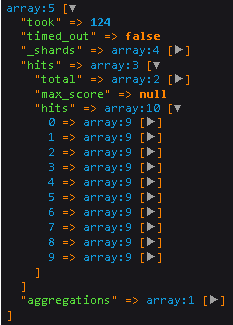
This concept was able to be reproduced by the explain feature of Elasticsearch search API
a sample screenshot of the search API response
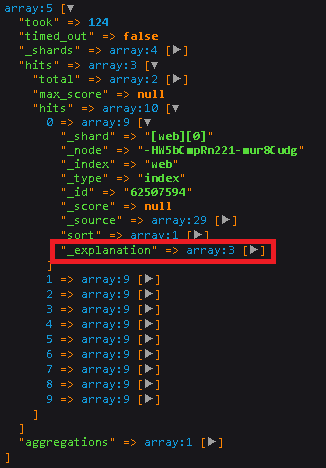
then here's a sample screenshot of the contents of the explain object
And that's how we were able to display the keyword frequency PER HIT / DOCUMENT
The problem with explain is that it appears on hits-level --- meaning on every hit only
Is there a way or a feature similar to explain that is appearing in the same level as the body so I can have a summarized result?
P.S. this is happening within just the search API, didn't need any other calls or endpoints




