Yes Exactly! (Waits for the transaction to complete but yes)
The demo is synchronous REST Calls so the Parent transaction waits for everything to complete
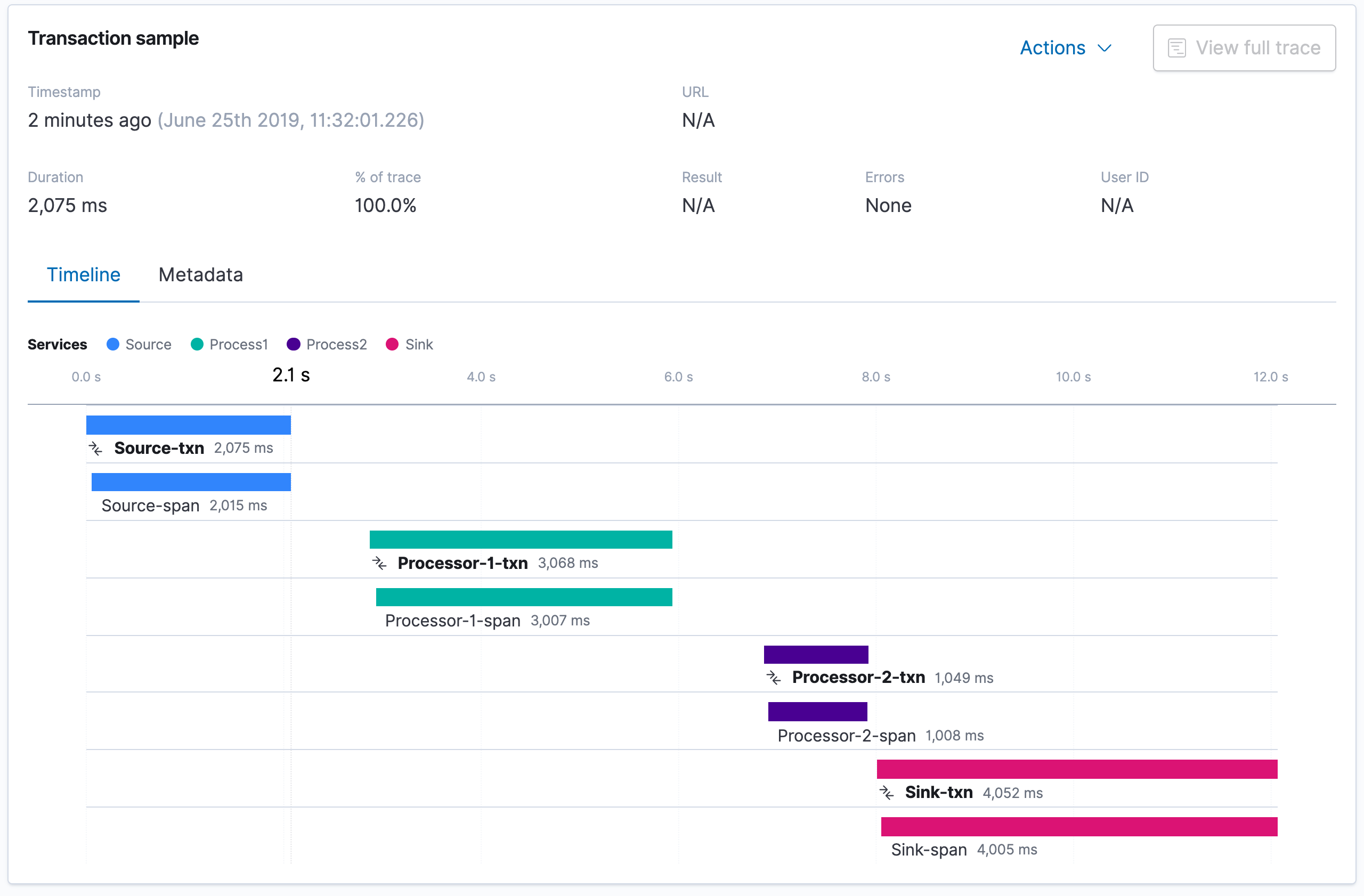
The process example is asynch.... Each process transactions complete but you still get the estimate of the overall trace time
Your process is asynch I believe ....
Calculating the total end-to-end trace time for a multi-service message-based asynchronous system where messages could sit in queues and it is never really clear when the trace ends...is not easy.... perhaps not really accurate/feasible.
One reason I believe is that you never really know when the last service is run... maybe it is sitting in a queue somewhere... the Waterfall shows that elaspsed time.. I just don't think the actual value is calculated... because there is no "finite finish" to it if 5 mins later another service ran with the same trace.id the waterfall would be updated.
This is different than a synchronous "waterfall" where there is a definite end.
BTW I just ran my processor and it still works with the latest java agent (not sure why I would have thought it would complain about my Header Handlers but in short I am passing in the correct values. This allowed me to test some things
$ TAG=1.39.0 ./run-pipeline.sh
a) But you can pretty easily sum the transactions times (what you would be missing is the queue delay)
b) You can also look pretty easily calculate the difference in time from the start of the first transaction to the start of the end transaction
c) Of course the real total elapsed time would be for a given trace.id NOT easy
Last Service Time stamp (max @timestamp ) - Originating service (max @timestamp) + Duration of the last service transaction.duration.us
I did create this table in Lens it is not exact ... it shows the sum of the transactions and the max timestamp (beginning of last transaction) - min timestamp (start of 1st transaction)
perhaps that will get you started
So this is my processor example which still seems to work

















{kind=link}