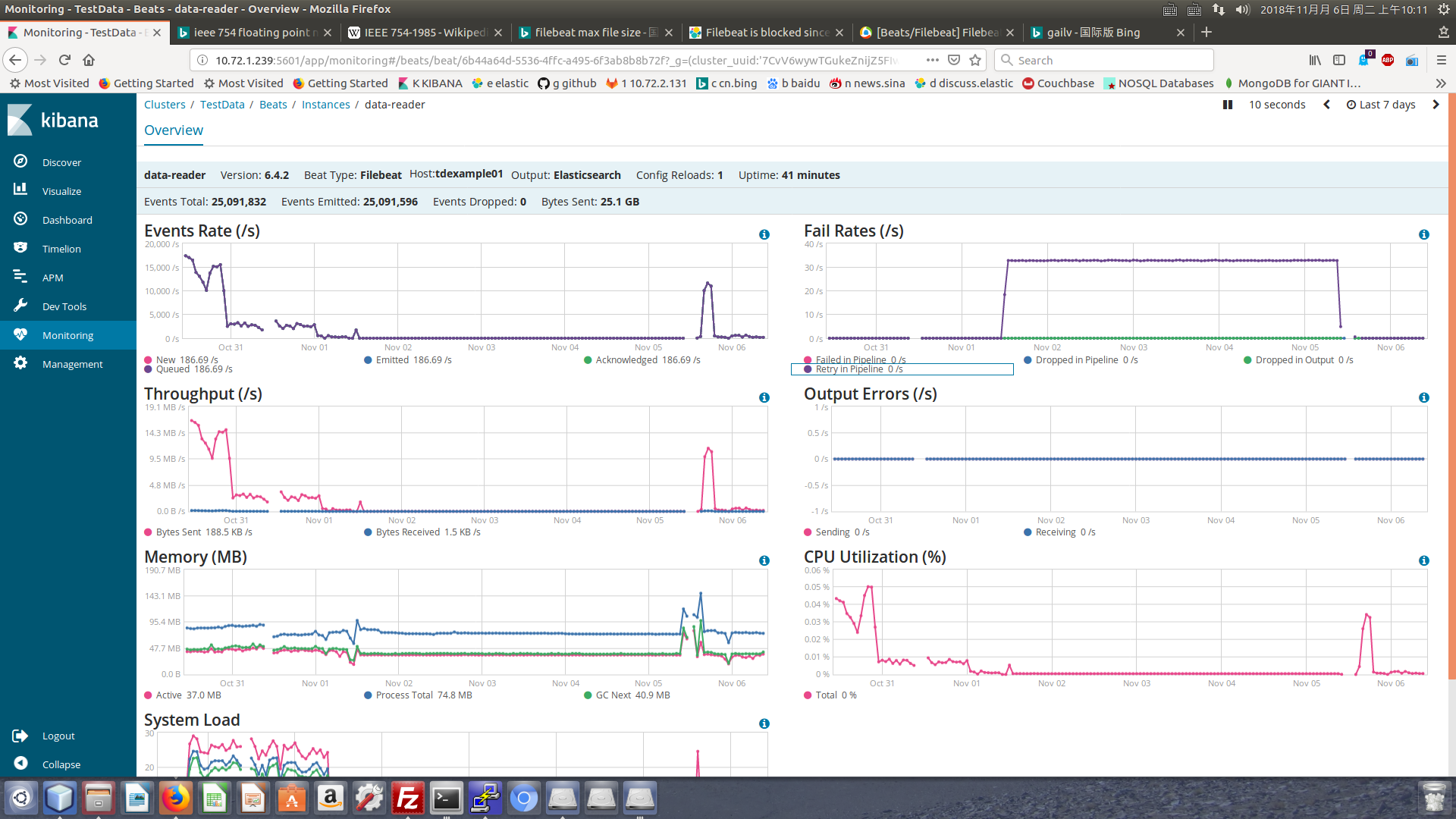
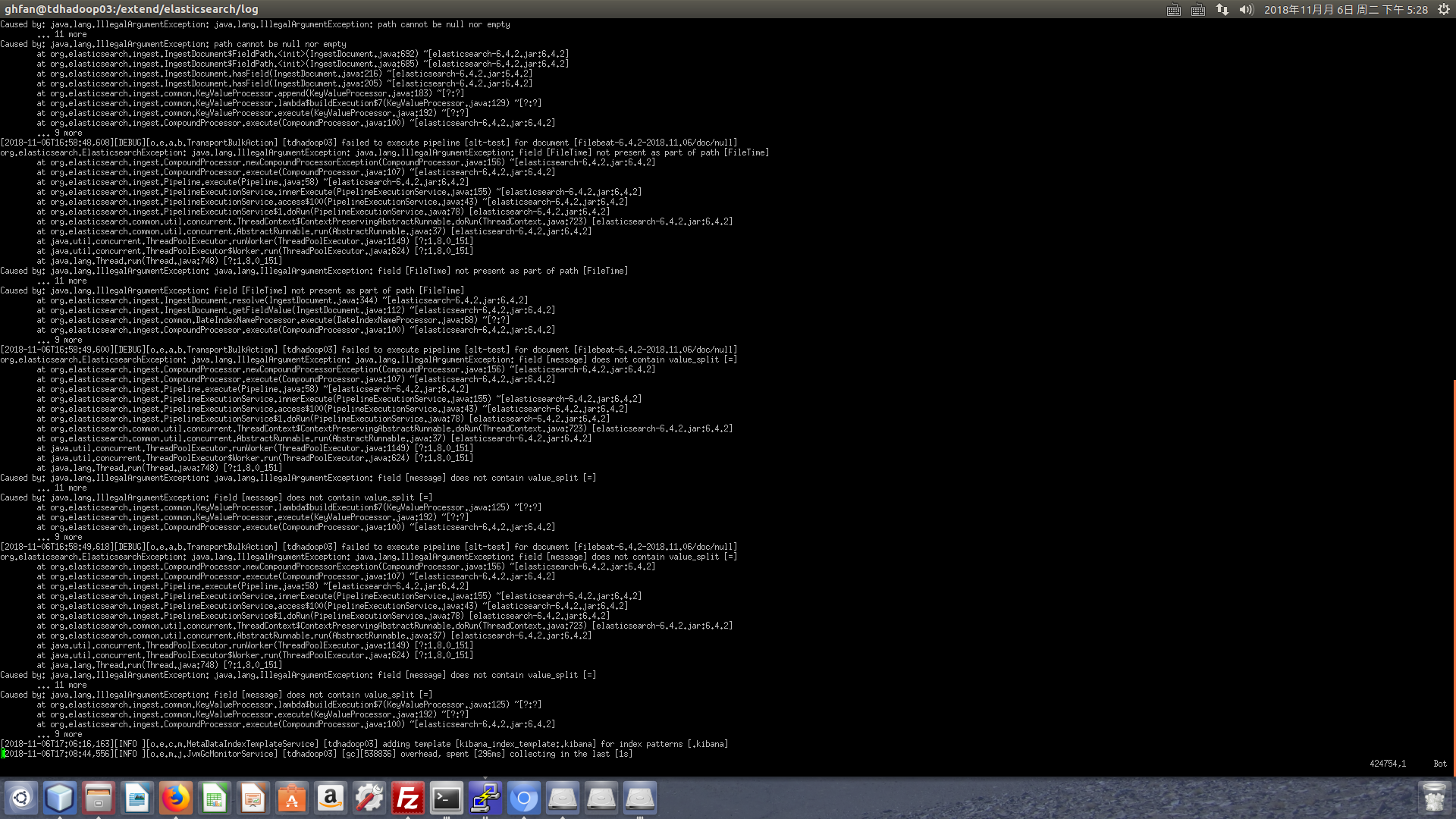
hi, thanks for your reply.
I just change the ingest pipeline configuration to catch and handle the error:
PUT _ingest/pipeline/slt-test
{
"description": "to parse the filebeat message",
"processors": [
{
"kv": {
"field": "message",
"field_split": ",",
"value_split": "=",
"on_failure" : [
{
"set" : {
"field" : "FileTime",
"value" : "2017-01-01T01:01:01.00+08:00"
}
}
]
}
},
{
"remove": {
"field": [
"prospector",
"beat"
]
}
},
{
"date_index_name": {
"field": "FileTime",
"index_name_prefix": "slt-test-",
"date_rounding": "M"
}
},
{
"fail": {
"message": "an error message=[{{message}}], source = [{{source}}], offset = [{{offset}}], FileTime =[{{FileTime}}]"
}
}
]
after the change, what I got from the elasticsearch log is this error, But I can not understand why this exception, actually I have ever just copy the ingest pipeline and rename to a new one, then the log file can be consumed by the elasticsearch, so I'm really confused to this exception, there are 3 processors in this pipeline and pass the first and don't know where it failed?
[2018-11-07T12:35:14,802][DEBUG][o.e.a.b.TransportBulkAction] [tdhadoop03] failed to execute pipeline [slt-test] for document [filebeat-6.4.2-2018.11.07/doc/null]
org.elasticsearch.ElasticsearchException: java.lang.IllegalArgumentException: org.elasticsearch.ingest.common.FailProcessorException: an error message=[LotNumber=CHARZ,Device=CHARZ,Program=MAIN,ProgramVersion=DNXDM1SLT_1.0.2,Tester=suzamdaslt088_010,TestCode=CCCCCP,Operation=CHARZ,FileTime=2018-09-06T05:07:40.00+08:00,Site=10,StartTestTime=2018-09-05T21:07:40.00+08:00,HBin=15,SBin=710028,SBinDesc=Test Fail Power Up1 Fail,HBinDesc=Fail,BinType=0,context=FinalPowerDown,generatedTestName=FinalPowerDown,Type=Test,result=1,alarm=0,TestTime=0.111], source = [/extend/data_log/SLT/CHARZ_CHARZ_UnknownUnitID_CHARZ_CCCCCP_YD1600BBM6IAE_20180906_050740_suzamdaslt088_010_MAIN.kdf.20181031191112.log], offset = [4574], FileTime =[2018-09-06T05:07:40.00+08:00]
at org.elasticsearch.ingest.CompoundProcessor.newCompoundProcessorException(CompoundProcessor.java:156) ~[elasticsearch-6.4.2.jar:6.4.2]
at org.elasticsearch.ingest.CompoundProcessor.execute(CompoundProcessor.java:107) ~[elasticsearch-6.4.2.jar:6.4.2]
at org.elasticsearch.ingest.Pipeline.execute(Pipeline.java:58) ~[elasticsearch-6.4.2.jar:6.4.2]
at org.elasticsearch.ingest.PipelineExecutionService.innerExecute(PipelineExecutionService.java:155) ~[elasticsearch-6.4.2.jar:6.4.2]
at org.elasticsearch.ingest.PipelineExecutionService.access$100(PipelineExecutionService.java:43) ~[elasticsearch-6.4.2.jar:6.4.2]
at org.elasticsearch.ingest.PipelineExecutionService$1.doRun(PipelineExecutionService.java:78) [elasticsearch-6.4.2.jar:6.4.2]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:723) [elasticsearch-6.4.2.jar:6.4.2]
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) [elasticsearch-6.4.2.jar:6.4.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_151]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_151]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_151]
Caused by: java.lang.IllegalArgumentException: org.elasticsearch.ingest.common.FailProcessorException: an error message=[LotNumber=CHARZ,Device=CHARZ,Program=MAIN,ProgramVersion=DNXDM1SLT_1.0.2,Tester=suzamdaslt088_010,TestCode=CCCCCP,Operation=CHARZ,FileTime=2018-09-06T05:07:40.00+08:00,Site=10,StartTestTime=2018-09-05T21:07:40.00+08:00,HBin=15,SBin=710028,SBinDesc=Test Fail Power Up1 Fail,HBinDesc=Fail,BinType=0,context=FinalPowerDown,generatedTestName=FinalPowerDown,Type=Test,result=1,alarm=0,TestTime=0.111], source = [/extend/data_log/SLT/CHARZ_CHARZ_UnknownUnitID_CHARZ_CCCCCP_YD1600BBM6IAE_20180906_050740_suzamdaslt088_010_MAIN.kdf.20181031191112.log], offset = [4574], FileTime =[2018-09-06T05:07:40.00+08:00]
... 11 more
Caused by: org.elasticsearch.ingest.common.FailProcessorException: an error message=[LotNumber=CHARZ,Device=CHARZ,Program=MAIN,ProgramVersion=DNXDM1SLT_1.0.2,Tester=suzamdaslt088_010,TestCode=CCCCCP,Operation=CHARZ,FileTime=2018-09-06T05:07:40.00+08:00,Site=10,StartTestTime=2018-09-05T21:07:40.00+08:00,HBin=15,SBin=710028,SBinDesc=Test Fail Power Up1 Fail,HBinDesc=Fail,BinType=0,context=FinalPowerDown,generatedTestName=FinalPowerDown,Type=Test,result=1,alarm=0,TestTime=0.111], source = [/extend/data_log/SLT/CHARZ_CHARZ_UnknownUnitID_CHARZ_CCCCCP_YD1600BBM6IAE_20180906_050740_suzamdaslt088_010_MAIN.kdf.20181031191112.log], offset = [4574], FileTime =[2018-09-06T05:07:40.00+08:00]
at org.elasticsearch.ingest.common.FailProcessor.execute(FailProcessor.java:52) ~[?:?]
at org.elasticsearch.ingest.CompoundProcessor.execute(CompoundProcessor.java:100) ~[elasticsearch-6.4.2.jar:6.4.2]
after check the details I found this error is about filebeat, document [filebeat-6.4.2-2018.11.07/doc/null], why there's any empty filebeat monitor message, and also it was send to my slt-test-* index?
so, I think this error may be caused by filebeat but not my log file or the configuration.
[2018-11-07T12:35:14,802][DEBUG][o.e.a.b.TransportBulkAction] [tdhadoop03] failed to execute pipeline [slt-test] for document [filebeat-6.4.2-2018.11.07/doc/null]