Hi,
Appreciate your fast response.
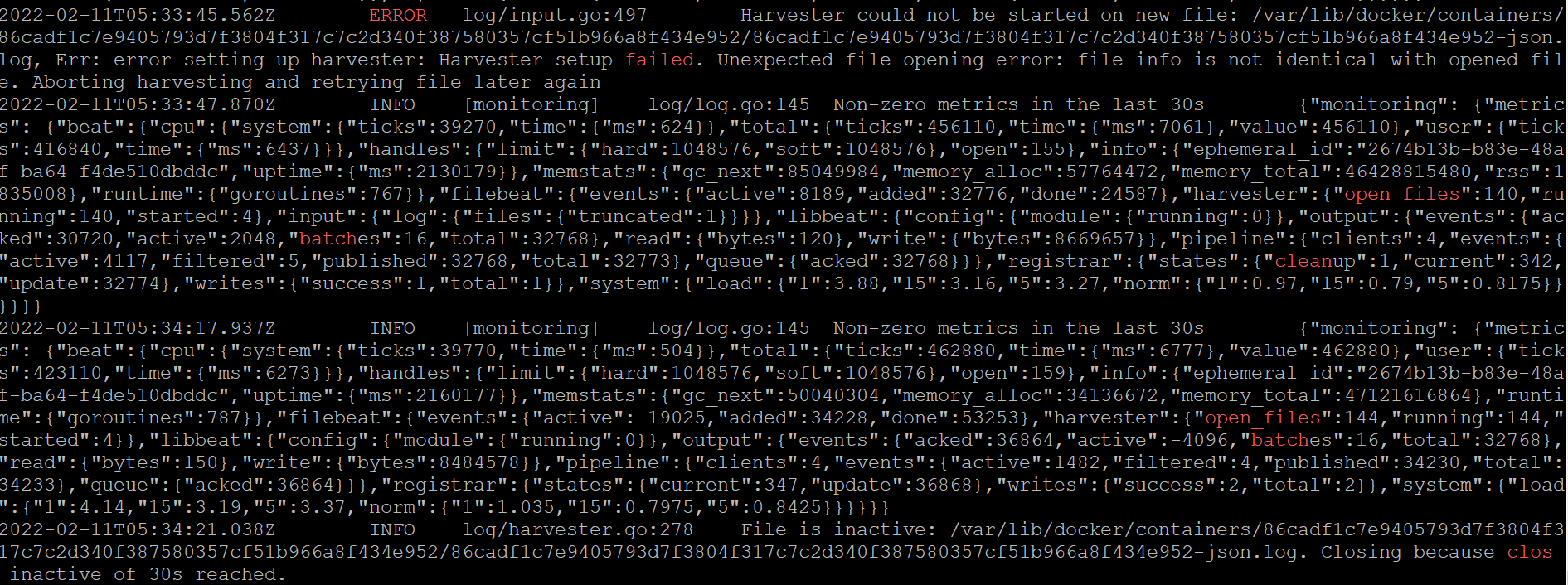
I don't see any contention in logstash or in Elasticsearch. I tried increasing the logstash pods and also increased the CPU limits for it. I also tried increasing the refresh_interval for the index and replica to zero so that ingestion is fast. But no luck so far.
Filebeat is able to send logs with decent rate for 5 to 10 minutes after restart but eventually it lags as the number of open files keeps on increasing. If Elasticsearch is causing the contention then I don't think filebeat will be able to send logs after restarts for 15 minutes. On some nodes where log rotation is not that fast its working fine.
Below is the filebeat configuration:
- type: container
containers.ids:
- "*"
paths:
- "/var/lib/docker/containers/*/*.log"
multiline.pattern: '^\[|^{|^\(|^[t]=|^text|^ERROR|^INFO|^DEBUG|^level=|^[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}|^[0-9]{4}-[0-9]{2}-[0-9]{2}|^\[[0-9]{4}-[0-9]{2}-[0-9]{2}|^[0-9]{2}:[0-9]{2}:[0-9]{2}|^[0-9]{2,3}.[0-9]{2,3}.[0-9]{2,3}|^[a-zA-Z]{1}[0-9]{4}|^[a-zA-Z]{3,4}\s[a-zA-Z]{3}|^[a-zA-Z]{2,3}-[a-zA-Z]{2,5}-[0-9a-z]{2,7}'
multiline.negate: true
multiline.match: after
clean_inactive: 61m #Tried multiple values from hours to minutes
ignore_older: 60m #Tried multiple values from hours to minutes
close_inactive: 1m #Tried multiple values from few minutes to 10 seconds
clean_removed: true
close_removed: true
processors:
- add_kubernetes_metadata:
in_cluster: true
- type: log
clean_removed: true
paths:
- /var/logs/*.log
output.logstash:
hosts: ["${LOGSTASH_HOST:mon-logstash}:${LOGSTASH_PORT:5044}"]
pipelining: 4 #Tried default to 6
worker: 6 #Again tried from default to 10
loadbalance: true
In addition to above i tried following filebeat configurations as well:
- max_bulk_size
- scan_frequency
- filebeat.registry.flush
- TTL in output.logash
Also, there are couple of thousands entries in filebeat registry file for the rotated log files as log files are renamed with same name.
Logstash 3 pods: CPU limit is 4
Elasticsearch 3 data pods: CPU limit 4:
I have few workarounds but want to know if you are aware of this kind of race conditions with filebeat.
Is there a way i can see if Logstash/Elastsearch is putting back pressure on filebeat?May be filebeat metrics?
Also, it seems logstash is not completely loadbalanced. I tried setting TTL but it didn't work as expected. May be if you can shed some light on that as well will be helpful.
Once again thank you and looking forward for your response.