Hi All,
I have a bit of a problem in terms of data ingestion using FileBeat. I have multiple directories from which I wish to read data in almost near realtime. Below is the relevant snippet from my filebeat.
=========================== Filebeat prospectors =============================
filebeat.prospectors:
- type: log
paths: ["/opt/elk/filebeat/av/*.log"]
tags: ["av"]
harvester_limit: 100
- type: log
paths: ["/opt/filebeat/websense/*.log"]
tags: ["websense"]
harvester_limit: 1000
- type: log
paths: ["/opt/elk/filebeat/waf/*.log"]
tags: ["waf"]
harvester_limit: 100
- type: log
paths: ["/opt/elk/filebeat/ad/*.log"]
tags: ["ad"]
harvester_limit: 1000
There are multiple files dumped in these paths every 5 mins. The problem is that the volume of files created in each directory is not uniform. The websense and ad logs are huge in volume and FileBeat is not able to cope with the increased volume. We often see a backlog of over 2-3 hours created in these two directories. PS: Removing the harvester_limit does not make a difference to the ingestion speed.
There are ample of idle resources on the FileBeat server.
root@BEATS01:~# iostat -c
Linux 4.4.0-127-generic (SIDCBEATS01) 08/16/2018 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.60 0.00 0.17 0.02 0.00 99.22
root@BEATS01:~# iostat -d
Linux 4.4.0-127-generic (SIDCBEATS01) 08/16/2018 _x86_64_ (4 CPU)
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
loop0 0.00 0.00 0.00 8 0
fd0 0.00 0.00 0.00 4 0
sda 1.94 69.40 226.27 18111418 59047540
dm-0 3.79 69.35 226.27 18098253 59047480
dm-1 0.00 0.01 0.00 3264 0
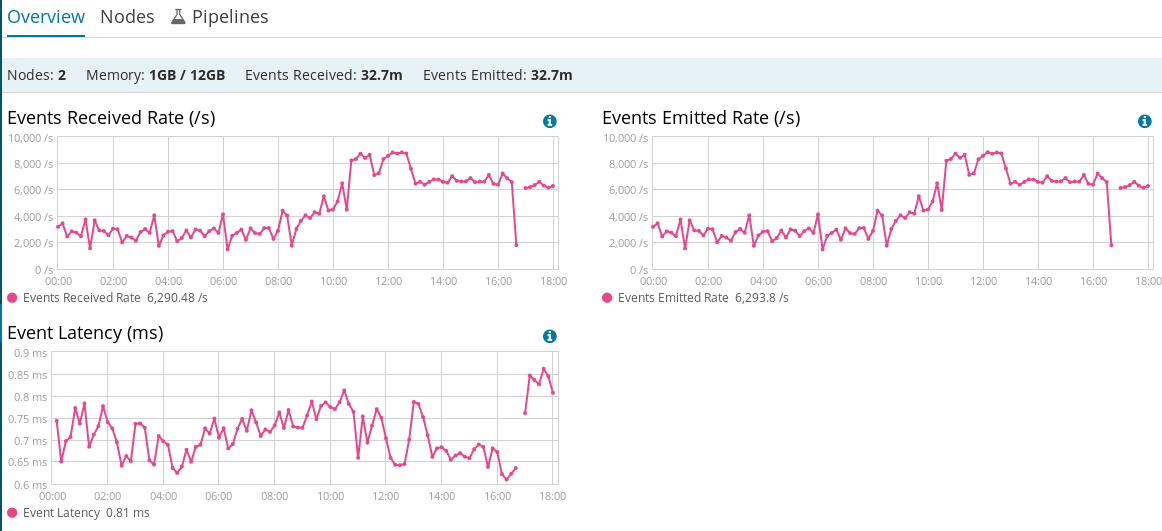
FileBeat at no point of time crosses more than 7k-8k EPS. While this is sufficient in normal operations, but during peak hours, it does not seem to scale to 10-12k EPS.
My setup is as follows:
- FileBeat servers - 2 - 4 vCPU - 8 GB RAM
- Logstash servers - 2 - 4 vCPU - 8 GB RAM
- Elasticsearch - 5 - 8vCPU - 32 GB RAM
Both Logstash and Elasticsearch are not overloaded and have plenty of resources.
Elasticsearch Overview:

Logstash Overview: