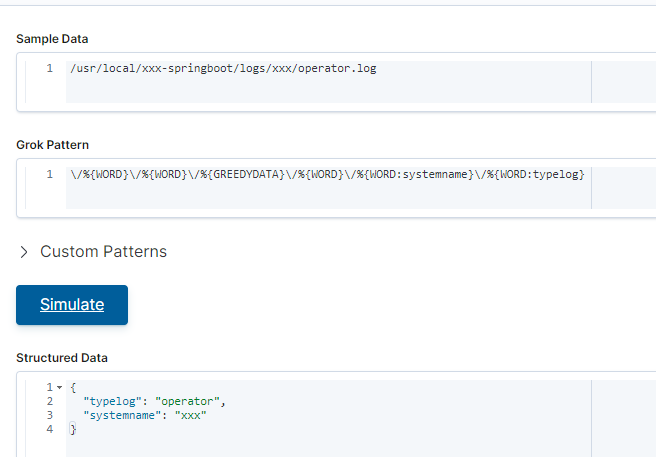
Thanks for your advice. I found the cause of the problem.I need to use as little %{WORD} as possible.
The %{WORD} used earlier may have mapped to the latter
But be careful with greedydata. It is an eqivalent vor * in underlying regex. If you have very long fields like stacktraces and you want to search something with greedydata, it may happen that logstash needs to parse the whole file and may fail at the end because it finds no match.
For all regex / grok try to set anchors like ^ or $ or static text if possible. Make it fail as fast as possible.
If you want to tune regex I can recommend regex101.com. It shows the number of steps needed. So you can find out wrong usage of greedydata (*) easily. But you have to convert grok to regex, which syntax is a bit different on defining the variables / regex groups.
I always try to to use greedydata as few as possible and rather use patterns like NOT_DASH to have anything until the given character.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.