Hi
I need a help for extract data from one of filed from CSV.
the header for these data presents like below:

EPS_BEARER_ID-BEARER_QCI-ARP_PL-ARP_PCI-ARP_PVI-GBR_UL-GBR_DL-BEARER_CAUSE-DEFAULT_BEARER_ID
5-7-undefined-undefined-undefined-undefined-undefined-#0(bearer successful)-5|7-5-undefined-undefined-undefined-undefined-undefined-#0(bearer successful)-7;
and this is the definition on particular fields:

but it uses a filter to clean up the data
which at a later stage arranges the field along with undefined entries on the whole plane "undefined"
mutate {
gsub => ["message","undefined-",""]
}
mutate {
gsub => ["message","[-]*undefined",""]
}
Let's assume that the fields look without "undefined" as shown below in the screenshot.
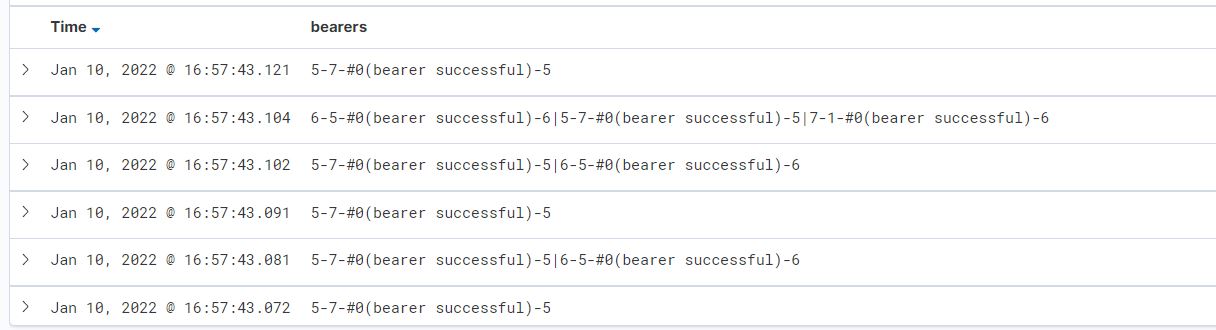
How can I separate these data so that they are presented according to the given pattern. The "undefine" fields introduce some order here but where they are not used they waste data stored in the elastic. Therefore, I would like to parse the data without them. But how to do it using ruby code?