I am processing log files.
Each line of the log files being processed contain an integer field called 'flag'.
One of the lines of each log contains a value 'JobID' that is extracted in the filter section of the pipeline. This value can, of course, be read in the output section.
Is it possible to use one of the output plugins to update the flag field in the all documents being sent to elasticsearch for a particular log file. The flag field needs to be updated to the 'JobID' value.
If the line that contains the JobId is in the first line of the file then you might be able to do it using an aggregate filter.
Otherwise I would look at pre-processing the log to extract the JobID, then using a translate filter to lookup the JobID associated with the file path.
I do not see anything in the documentation for logstash aggregate filter that would allow me to update the 'flag' field value in each line of the log to the 'jobId' value extracted at the very beginning.
What am I missing?
I have to do something similar in one of my logs. My problem though, is that my "JobID" field isn't usually the first line of the file.
But here is my solution that works whether it is the beginning or the middle of the file.
filter {
grok {
match => { "message" => "ComputerName:%{GREEDYDATA:computer}" }
add_tag => ["computer_line"]
}
mutate { add_field => { "TaskId" => "all" }}
aggregate {
task_id => "%{TaskId}"
code => "
map['computer'] = nil
map_action => "create"
"
}
if "computer_line" in [tags] {
aggregate {
task_id => "%{TaskId}"
code => "map['computer'] = event.get('computer')"
map_action => "update"
remove_field => ["TaskId"]
}
}
else {
aggregate {
task_id => "%{TaskId}"
code => "
event.set('computer', map['computer'])
"
map_action => "update"
remove_field => ["TaskId"]
remove_field => ["Path"]
}
}
}I do this for several dozens of lines.
I am using a file input, so [path] is a constant.
grok { match => { "message" => "JobId: %{NUMBER:jobID}" } }
aggregate {
task_id => "%{path}"
code => '
map["jobID"] ||= ""
jobID = event.get("jobID")
if jobID
map["jobID"] = jobID
else
event.set("jobID", map["jobID"])
end
'
}
This is relying on the ordering of events, which logstash does not guarantee. You can get away with it if you configure logstash to use a single pipeline.worker thread.
I am dealing with logs that have the following structure (the format of the first line is guaranteed).
2019-01-15 09:00:11.6109 INFO 1 | JobId=57 Status=Starting
2019-01-15 09:00:11.6439 INFO 1 | DatabaseFactoryFileName= JobName=FileDownloader JobId=57 QuantIndexDatabaseName=Reference ReportLocation=
2019-01-15 09:00:11.6439 INFO 1 | JobId=57 Status=Started
2019-01-15 09:00:11.6439 INFO 1 | FtpServer:Bloomberg-auto_1.link.hedani.net, DownloadFiles:System.Collections.Generic.List`1[System.String], DestinationFolder:\vfnpri30cifschpA.gbl.ad.hedani.net\QT-AMER$\Support\Archive\Toolbox\Bloomberg
2019-01-15 09:00:12.8549 INFO 1 | Time 20190115 17:00:12
2019-01-15 09:00:15.7342 INFO 1 | DownloadFileName equity_asia1.cax.gz
.
. a lot more lines
The field between LOGLEVEL and pipe symbol (called 'flag') is there for each line of the log and needs to be updated to the jobID before outputting to the elasticsearch index (in this case all the 1's should be updated to 57.
I attempted to adapt your suggested code to do this as follows. It does not work - why?
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:logTimestamp}\s%{LOGLEVEL:log-level}\s+%{NUMBER:flag}\s%{NOTSPACE:flag2X}\s%{WORD:jobIdPrompt}%{DATA:equal1}%{NUMBER:jobID}\s%{WORD:jobStatusPrompt}%{DATA:equal2}%{WORD:jobStatus}" }
match => { "message" => "%{TIMESTAMP_ISO8601:logTimestamp}\s%{LOGLEVEL:log-level}\s+%{NUMBER:flag}\s%{GREEDYDATA:msg}" }
}
aggregate {
task_id => "%{path}"
code => '
map["jobID"] ||= ""
jobID = event.get("jobID")
if jobID
map["jobID"] = jobID
else
event.set("flag", map["jobID"])
end
'
}
}
If you set two 'match => "..."' options then the first one is ignored. Also, it is more efficient to anchor your grok patterns with ^ if you are matching from the start of the line. Also, do not feel you have to consume everything using patterns. Using fixed strings is also more efficient since it reduces back tracking when failing to match.
grok {
match => { "message" => [
"^%{TIMESTAMP_ISO8601:logTimestamp}\s%{LOGLEVEL:log-level}\s+%{NUMBER:flag}\s\|\sJobId=%{NUMBER:jobID}\sStatus=%{WORD:jobStatus}",
"^%{TIMESTAMP_ISO8601:logTimestamp}\s%{LOGLEVEL:log-level}\s+%{NUMBER:flag}\s\|\s%{GREEDYDATA:msg}"
]
}Here is a simplified log:
2019-01-15 00:30:30.0850 INFO 1 | JobId=60 Status=Starting
2019-01-15 00:30:30.1180 INFO 1 | Here is some stuff
2019-01-15 00:30:30.1180 INFO 1 | JobId=60 Status=Started
2019-01-15 00:30:30.1230 INFO 1 | Here is some more stuff
2019-01-15 00:30:31.3220 INFO 1 | More stuff again 2
2019-01-15 00:30:31.4721 INFO 1 | More stuff again 3
2019-01-15 00:30:33.9892 INFO 1 | More stuff again 4
2019-01-15 00:31:10.6749 INFO 1 | More stuff again 5
2019-01-15 00:38:49.9096 INFO 1 | JobId=60 Status=Completed
2019-01-15 00:38:49.9096 ERROR 1 | More stuff again 9
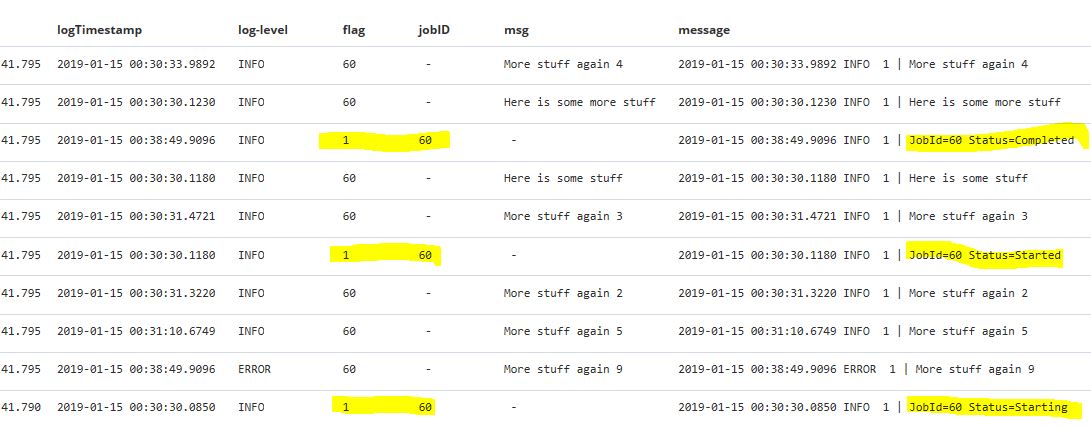
Here is the grok (modified as you suggested) and the aggregate filter I attempted to modify ( a guess) to set the flag field to the jobID harvested from the first line of the log. The result is shown below (image of discover). How can the aggregate filter be modified to set the flag field to the harvested jobID?
grok {
match => { "message" => [
"^%{TIMESTAMP_ISO8601:logTimestamp}\s%{LOGLEVEL:log-level}\s+%{NUMBER:flag}\s\|\sJobId=%{NUMBER:jobID}\sStatus=%{WORD:jobStatus}",
"^%{TIMESTAMP_ISO8601:logTimestamp}\s%{LOGLEVEL:log-level}\s+%{NUMBER:flag}\s\|\s%{GREEDYDATA:msg}"
]
}
}
aggregate {
task_id => "%{path}"
code => '
map["jobID"] ||= ""
jobID = event.get("jobID")
if jobID
map["jobID"] = jobID
else
event.set("flag", map["jobID"])
end
'
}

That suggests that your events do not have a field called path. If the task_id does not exist the aggregate does not execute. You need a field that is common to the events you want to aggregate.

Do you really have periods in the field name or do you mean "%{[log][file][path]}" ?
It looks like "%{[log][file][path]}" is the right call.
Almost home.
How is this filter adjusted so that flag is completely updated properly (60 appears instead of 1 in the 3 highlighted lines)
aggregate {
task_id => "%{[log][file][path]}"
code => '
map["jobID"] ||= ""
jobID = event.get("jobID")
if jobID
map["jobID"] = jobID
else
event.set("flag", map["jobID"])
end
'
}
if jobID
map["jobID"] = jobID
end
event.set("flag", map["jobID"])