Hello,
I have installed Jaeger with an Elasticsearch storage backend in Kubernetes (AWS EKS). I have 8 r5.4xlarge nodes and Elasticsearch version 7.16.2 (docker.elastic.co/elasticsearch/elasticsearch:7.16.2). The deployment is done using the Elasticsearch helm chart (helm-charts/elasticsearch at main · elastic/helm-charts · GitHub). The values I have overridden are:
elasticsearch:
replicas: 4
minimumMasterNodes: 3
volumeClaimTemplate:
accessModes: ['ReadWriteOnce']
resources:
requests:
storage: 2000Gi
resources:
requests:
cpu: '5000m'
memory: '32Gi'
limits:
cpu: '8000m'
memory: '32Gi'
esJavaOpts: '-Xmx16g -Xms16g'
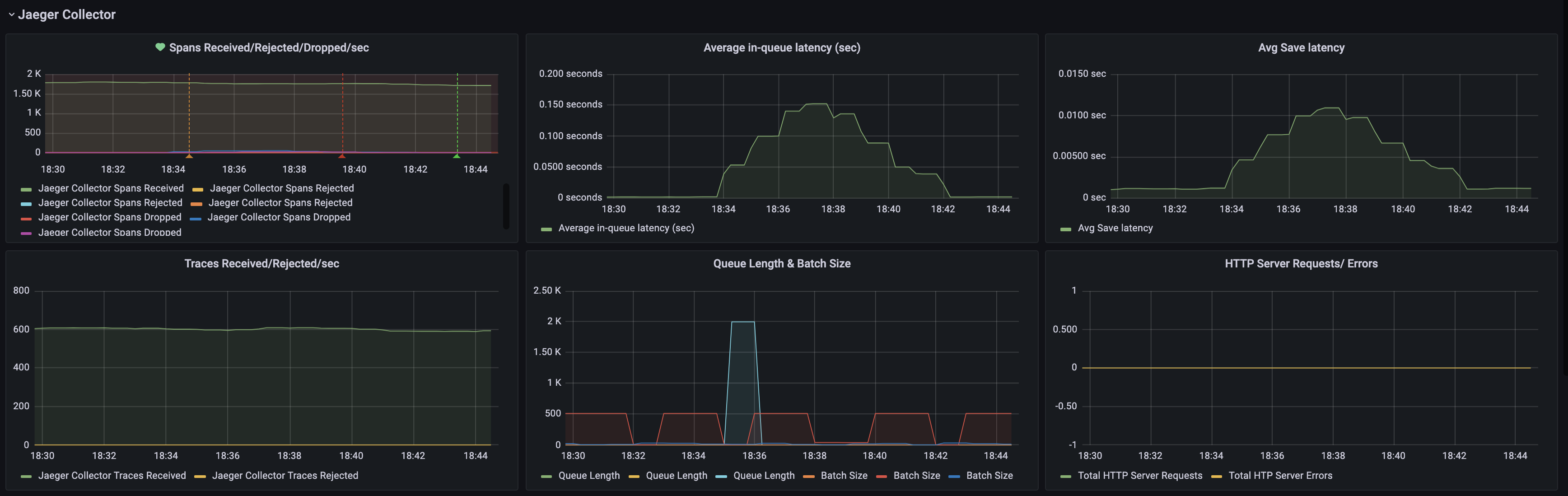
I have been seeing periodic dropping of spans, correlating with a spike in in-queue and save latency. Save latency, particularly is an indication that the storage backend isn't able to keep up. Additionally, the spikes correlate with an increase in flush operation timing. Also, the index write's memory steadily increases until the flush, when it drops and we have a drop in spans and spikes in latency. I don't have much experience with Elasticsearch, so any help/guidance is appreciated!
I have attached some screenshots of our Jaeger and Elasticsearch dashboards.

 )
)