Hello,
At the customer site, we are using ElasticStack to gather syslogs from the network devices.
Logstash is receiving around 4000 syslogs/sec. We are using Logstash version 6.8.8.
The problem is that every 2-5 hours Logstasha workers start to die out until every worker dies and no more syslogs are received.
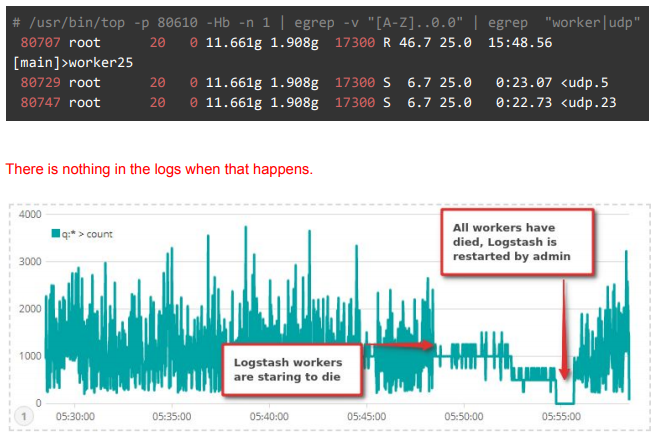
Logstash is on a dedicated server, Elasticsearch Master + Kibana is one server, and we have 2
Elasticsearch node servers.
Logstash x 1
CPU: 4 x Intel(R) Xeon(R) CPU E5-2665 0 @ 2.40GHz
RAM: 8G
DISK: 20G`

Kibana + Elasticsearch Master x 1
CPU: 4 x Intel(R) Xeon(R) CPU E5-2665 0 @ 2.40GHz
RAM: 8G
DISK: 20G
OS: CentOS
Elasticsearch Node x 2
CPU: 4 x Intel(R) Xeon(R) CPU E5-2665 0 @ 2.40GHz
RAM: 16G
DISK: 20G za OS i 800G za data
OS: CentOS

more /etc/logstash/logstash.yml
pipeline.batch.size: 250
pipeline.batch.delay: 50
pipeline.unsafe_shutdown: true
pipeline.workers: 30
path.data: /var/lib/logstash
config.reload.automatic: true
config.reload.interval: 10s
path.logs: /var/log/logstash
more /etc/logstash/jvm.options
-Xms7096M -Xmx7096M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
-Djava.awt.headless=true
-Dfile.encoding=UTF-8
-Djruby.compile.invokedynamic=true
-Djruby.jit.threshold=0
-XX:+HeapDumpOnOutOfMemoryError
-Djava.security.egd=file:/dev/urandom
Can you please help me troubleshoot this issue?
Thank you.
Reagards