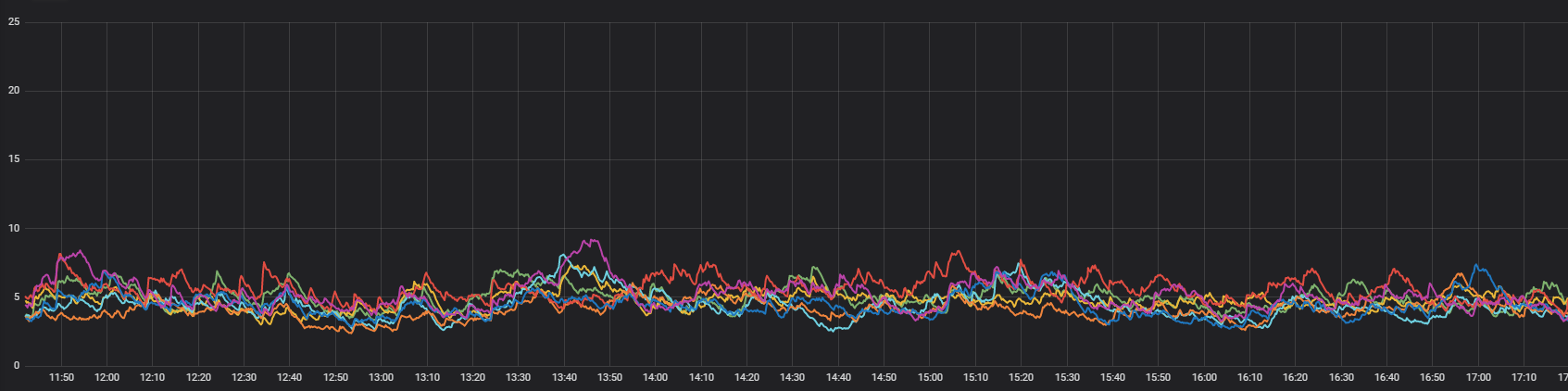
У человека такая же ситуация: [6.8.2] Unusual Server Load
Проанализировал разницу между нагрузкой на нодах. CPU и диски загружены одинаково. Раница существенная в Load Average и Context switсhes. На высоконагруженной ноде всё в среднем в 2-2.5 раза больше.
Могу прислать hotthreads со всех нод
Присылайте, посмотрим.
Hot threads(hot_threads?threads=9999) для всех нод:
node00 https://gist.github.com/UkrZilla/712778936148e697a156d13086504931
node01 https://gist.github.com/UkrZilla/a72e39456acdf5024bcc7d9529318878
node02 https://gist.github.com/UkrZilla/607ac7f8475068d4e0941c9dac57907f
node03 https://gist.github.com/UkrZilla/c606d7b7bf469c61abfd349d9a579aff
node04 https://gist.github.com/UkrZilla/56fea57082e788ccc311b80f6bc0c91f
node05 https://gist.github.com/UkrZilla/29202c6ef0095ba79f8548559534669b
node06 https://gist.github.com/UkrZilla/d2d6b5de1de7f7f273ea56208bb625fa

Как у вас распределены шарды индекса gameplay.raid.globalevents_201908_1?
Извиняюсь что картинкой
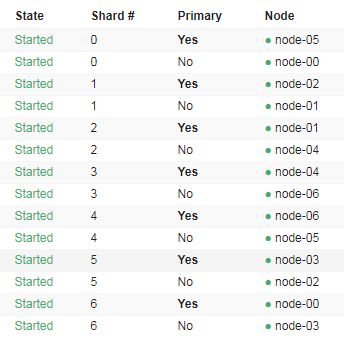
Странно, нагрузка в основном наблюдается от операции merge на этом индексе. Но вроде он нормально распределен. Это физическое железо или виртуалки?
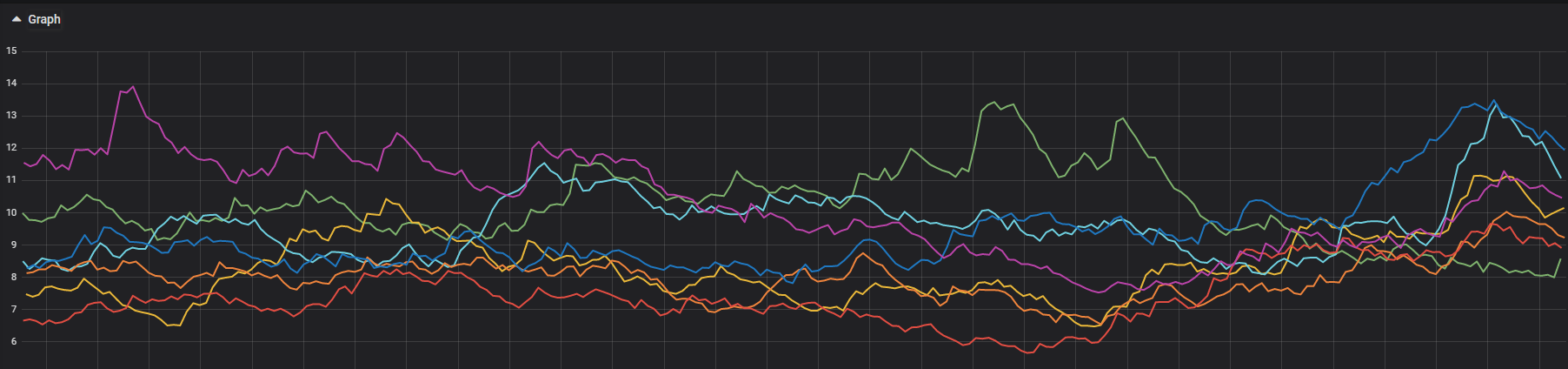
Прошла неделя с более приемлимой нагрузкой. Создались новые недельные и ндексы и ситуация опять повторяется. На скриншоте load average по нодам. И опять же нода с большей нагрузкой почему-то мёржит инексы, хотя другие ноды это успевают быстрее сделать
Что мне ещё предоставить?

Постараемся обновиться до 7-ки в начале следующей недели, но не думаю что этот баг там пофиксили. Иначе бы выпустили версию и для 6-ки с багфиксом
Насколько я понимаю это связано с огромными размерами наших нард
Спасибо
Это далеко не факт, я не помню чтобы какие-то сообщения пробегали о том, что это широко-распространненая проблема, и к безопасность она никакого отношения не имеет. Так что если что-то и улучшили, то могли в 6-ку не добавить.
Да, у нас не типичный случай) Тогда обновляемся в понедельник на 7.3.2
Сообщу о результатах

Вы пытались анализировать распределение шард и смотреть какой индекс вызывает такое поведение.
Как и в прошлый раз - все шарды равномерно распределены по нодам. Индексов несколько и они самые большие. Такое ощущение, что нода ведёт себя как будто вручную на индексах запустили merge, но только на одной ноде. Включил ежедневное создание индексов и сервис начал писать в новые индексы, но та нода продолжает делать merge индексов в которые уже не идёт запись

Забавно. А у вас там какой-нибудь curator или ILM не настроен старые индексы до одного сегмента сливать?
Тоже думал так, очень похоже. Когда-то делали forcemerge, но на таких объёмах это делать бесполезно: занимает много места и памяти.
В ILM нет ни одной policy. Curator не используем