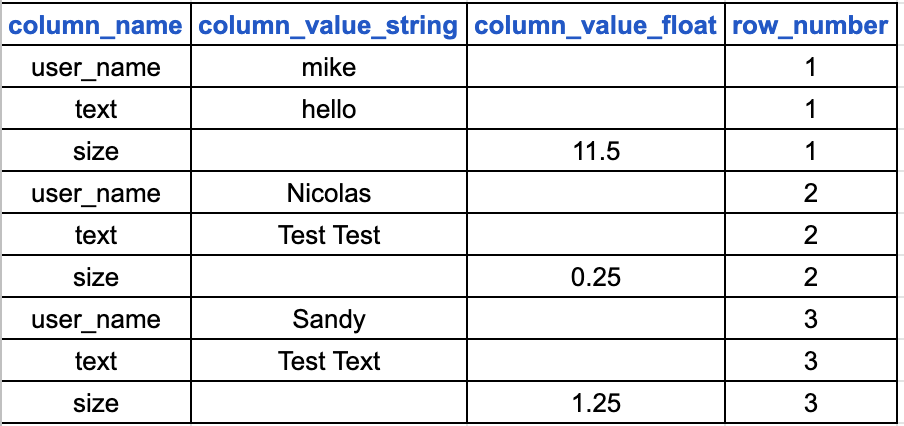
The input will stay as a csv file like this:
user_name,text,size
Mike,Hello,11.5
Nicolas,Test Test,0.25
Sandy,Test text,1.25
and the output would be a json file (because I want to push it to elasticsearch to do aggregations on it), the json schema will something like this (auto row detection and put it in the output):
[
{
"column_name": "user_name",
"column_value_string": "mike",
"column_value_float": null,
"row_number": 1
},
{
"column_name": "text",
"column_value_string": "hello",
"column_value_float": null,
"row_number": 1
},
{
"column_name": "size",
"column_value_string": "",
"column_value_float": 11.5,
"row_number": 1
},
{
"column_name": "user_name",
"column_value_string": "Nicolas",
"column_value_float": null,
"row_number": 2
},
{
"column_name": "text",
"column_value_string": "Test Test",
"column_value_float": null,
"row_number": 2
},
{
"column_name": "size",
"column_value_string": "",
"column_value_float": 0.25,
"row_number": 2
},
{
"column_name": "user_name",
"column_value_string": "Sandy",
"column_value_float": null,
"row_number": 3
},
{
"column_name": "text",
"column_value_string": "Test Text",
"column_value_float": null,
"row_number": 3
},
{
"column_name": "size",
"column_value_string": "",
"column_value_float": 1.25,
"row_number": 3
}
]