I'm new elasticsearch user and i'm in charge to develop a system to monitoring our customers logs. So starting by this point i have to monitoring Fortinet Firewall Logs and i've already did with filebeat sending directly to elasticsearch. I have one index with 3 or 4 customers sending logs simultaneoustly and i need to split them to see their log size by customer. Someone can help me, please ? Or maybe a way to query via console
It all comes down to how precise you need to be. It's very simple to just create a percentage of the total logs by customer as a count by customer terms query or Lens visualization and then that's their percentage of the total storage / cost..
It can be that simple if you want.
Firewall logs tend to even out in size across the landscape.
So if that's good enough, no need to even break up the index. It'll save you a lot of other trouble
If you need to know the exact bytes ( which in the end may give you some tiny percentage of precision better) than you will have to break up into separate indices.
Based on your answer i don't need to get the exact amount of data, a percentage's sufficient for me. Can you show me how can i get this percentage without split indices ?
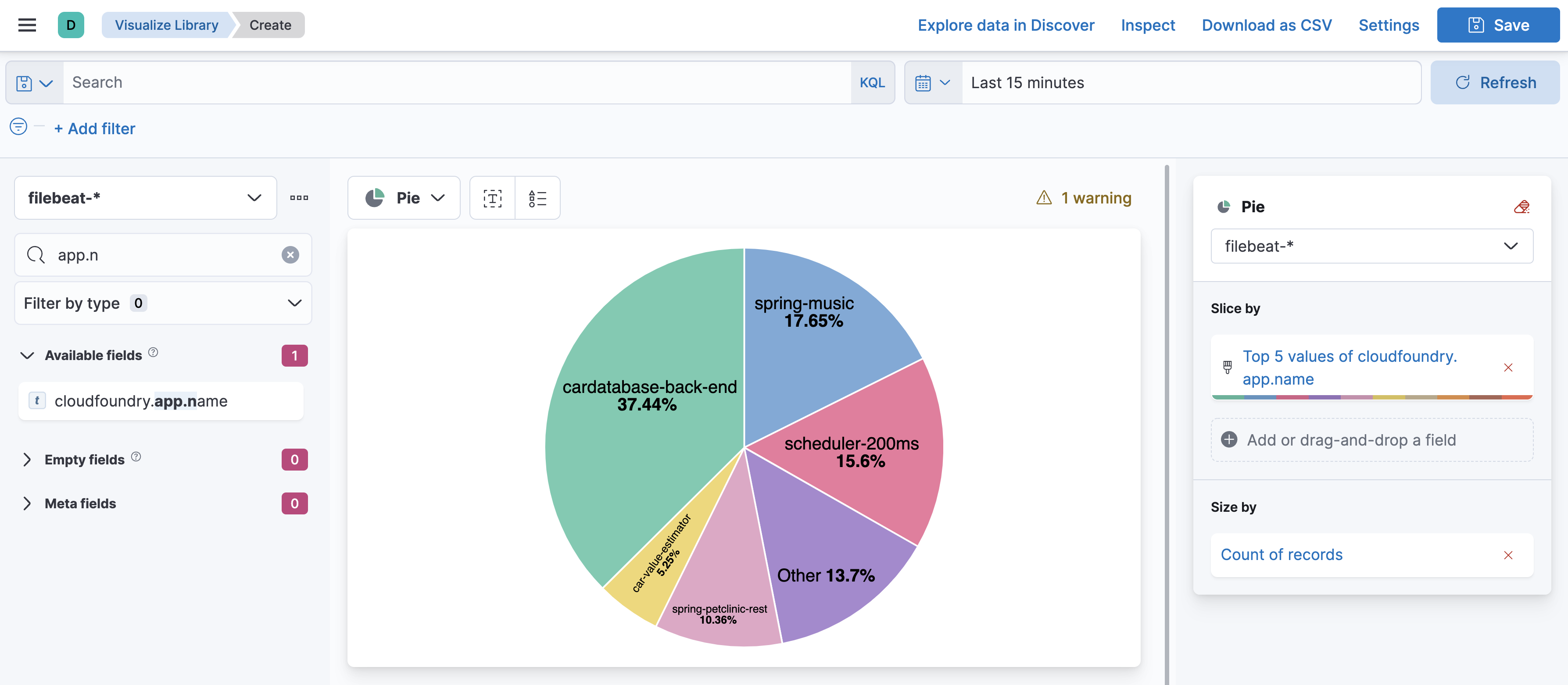
My infraestructure: Filebeat sends log directly to elasticsearch and parsing the data with "Fortinet Module". I have one field that brings info about customers, in this case "observer.name" field where i can see the name of the customer firewall present in all log entries. I already did a pie with percentage like you, but i would like to know if there is a way to put it in KB/MB/GB form instead percentage.
Ok Yes but it is not super clean... and requires a manual steps
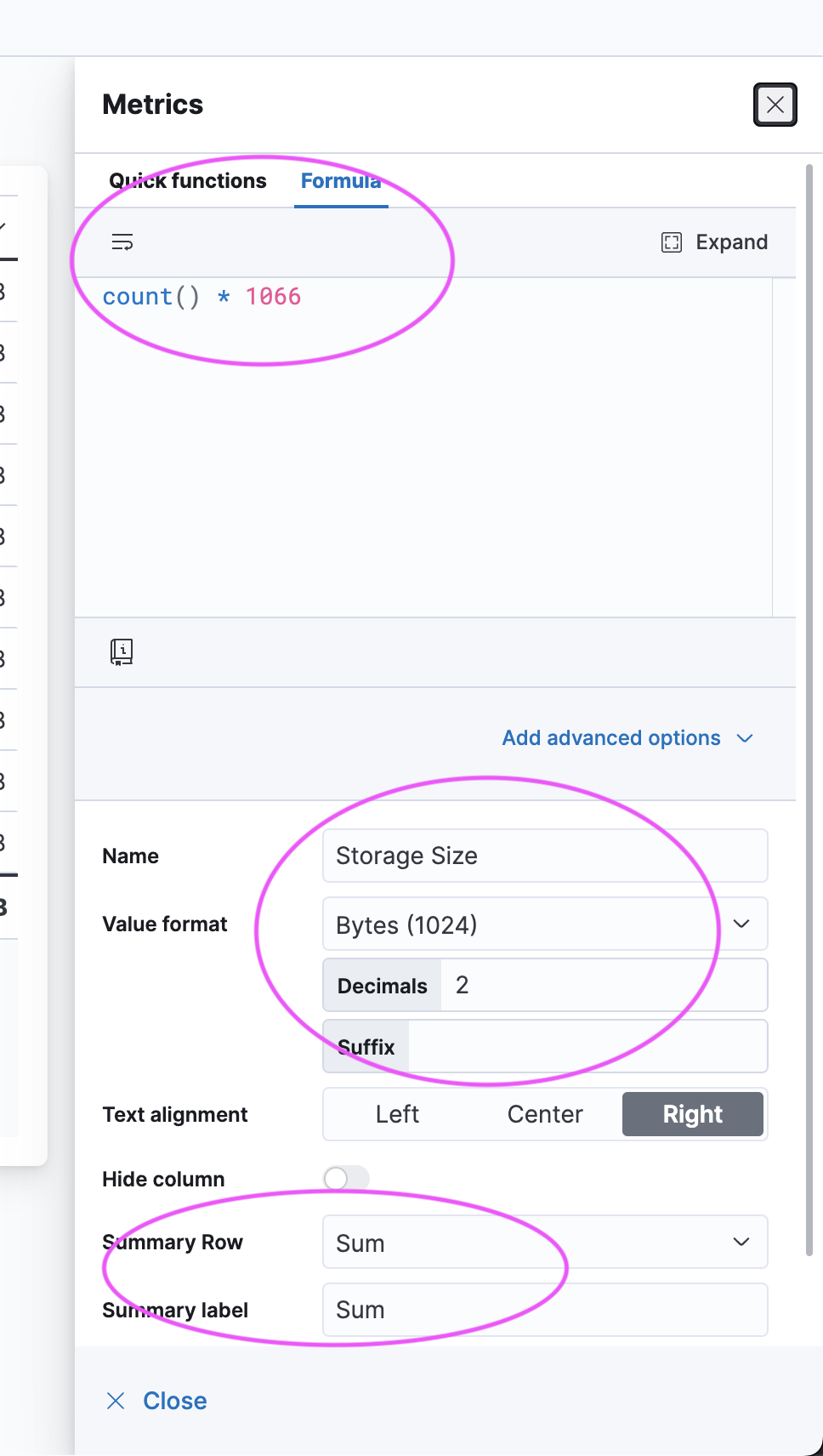
In general your will calculate the avg bytes / log then create a visualization that can show overall storage
So First run this command in Kibana - Dev Tools the bytes=b means it will show storage in bytes this is sorted by largest but you can also just s=index to sort by index
GET /_cat/indices/*?v&s=pri.store.size:desc&bytes=b
Example My Results
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .ds-filebeat-8.2.3-2022.08.06-000146 e1us_WnaRJa26jlYejAxNA 3 1 11447320 0 12206153071 6103214925
green open .ds-filebeat-8.2.3-2022.08.07-000149 Z51Vz3VWRRCrmoXJVAajPg 3 1 11433071 0 12194502328 6096678843
So then do the math... the store.size is the size of the primary plus what ever replicas... You can use either but the total storage is store.size
so for me
Avg Bytes / Doc = 12206153071 bytes / 11447320 Docs = 1066 Bytes / Doc for prim+replicas
(~500bytes/log primary is very typical)
So then lets make a Lens Table I am basing my on App Name but you can use Customer
This is a table but same for Pie Chart etc..etc..
NOTE : This is for the Time period of the Time Picker so keep that in mind
Okk! I'm going to try to apply this solution today, but looking at it, it seems to me that it will work that way. I will return when i apply these steps.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.