okok. I tried my best to keep it simple and understandable.
And one more doubt David. Why is the size of files increased when indexed ?
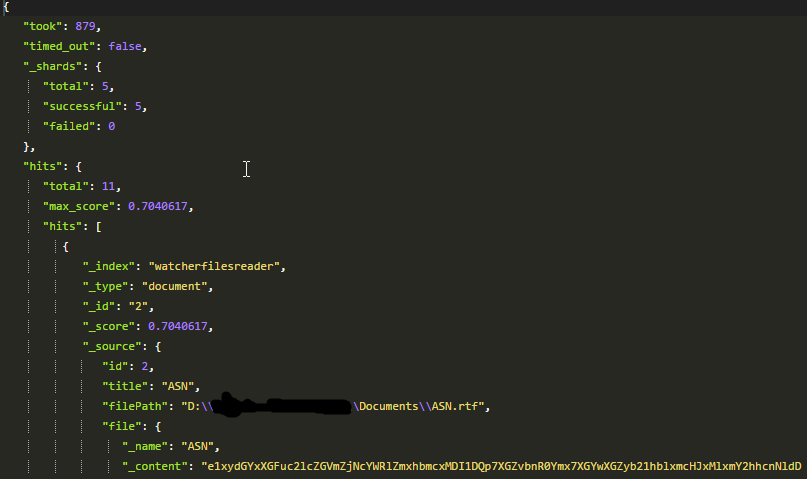
The total size of the folder from which documents are indexed is 30mb. But the head plugin is showing 127mb for the same number of files(which are indexed from the same folder)
The only way ATM to remove the BASE64 from the document is to source exclude.
Note that you are highlighting on the extracted content file.content which is generated at index time but you are not highlighting on file which has the BASE64 text.
So you are also storing file.content which requires more space obviously even if it's compressed on disk.
hi David,
I observed this while indexing the documents.
(Dont know if I'm correct with this) When I indexed the documents using manual id, the size is around 36mb but when I remove the Id field and index(auto generate the id), then it is taking so much time to index, the size is more and also the search function is not working properly. Does it depend on how the file is indexed?)
Hi David,
Here is the code how I'm giving manual id's for the documents indexed. But when I comment out Id field in all the occurrences in the below snaps, It is supposed to be autogenerated and it is autogenerating..
class Document
{
public int Id { get; set; }
public string Title { get; set; }
public string FilePath { get; set; }
public Attachment File { get; set; }
}
Mappings:
var createIndexResponse =
client.CreateIndex(defaultIndex, c => c
.Mappings(m => m
.Map<Document>(mp => mp
.Properties(ps => ps
.Number(n => n.Name(e => e.Id))
.String(s => s.Name(e => e.Title))
While Indexing: (where counter =1 on start)
foreach (string file in filesList)
{
Attachment attach = new Attachment
{
Name = Path.GetFileNameWithoutExtension(file),
Content = Convert.ToBase64String(File.ReadAllBytes(file)),
ContentType = Path.GetExtension(file)
};
var doc = new Document()
{
Id = counter,
Title = Path.GetFileNameWithoutExtension(file),
FilePath = Path.GetFullPath(file), //added to get the path of the file
File = attach
};
list.Add(doc);
counter++;
}
var response = client.IndexMany(list, "indexname");
I tried it. As there are no attachments the docs got indexed in the same time.
And the size differs only by 6kb (custom id-36kb where as autogen id 30kb for a total of 50docs with fields like title and filePath)
I dont know how to do it using shell script. In the above code snippets i just commented unnecessary fields and then indexed the documents and this is what I observed.
I tried to index docs using sense plugin.
with user defined id of 1
PUT abc/docs/1
{
"title":"trial1"
}
Without user defined id
PUT abc/docs/
{
"title":"trial1"
}
Then it threw this error: No handler found for uri [/abc/docs/] and method [PUT]
Sorry if I was unclear but this is not what I was expecting from you.
You told that you have a problem when you index data containing attachments.
When you define the _id it takes a way lesser space on disk than when you don't define the _id.
I asked to reproduce this with a full script.
Which basically means create a script like:
DELETE index
PUT index
{
"mappings": ... // Your mapping here
}
PUT index/doc/1
{
"attachment": "BASE64 content"
}
GET _cat/indices/index?v
Attach the output of the later command.
Then run:
DELETE index
PUT index
{
"mappings": ... // Your mapping here
}
POST index/doc
{
"attachment": "BASE64 content"
}
GET _cat/indices/index?v
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.