I have a cluster with 6 workers
I created 3 data nodes and 3 master nodes on them
When cluster nodes fail
The operator does not create termination pods in other nodes
It also has trouble rebuilding Kibana pods
Also, it does not detect any action for metricbeat pods on damaged nodes
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/elasticsearch-es-data-0 1/1 Running 0 6d5h 10.72.8.107 opkbwfpspst0109 <none> <none>
pod/elasticsearch-es-data-1 1/1 Running 0 6d5h 10.72.14.124 opkbwfpspst0107 <none> <none>
pod/elasticsearch-es-data-2 1/1 Terminating 0 5d3h 10.72.3.198 opkbwfpspst0111 <none> <none>
pod/elasticsearch-es-master-0 1/1 Running 0 6d5h 10.72.6.225 opkbwfpspst0105 <none> <none>
pod/elasticsearch-es-master-1 1/1 Terminating 0 6d5h 10.72.9.139 opkbwfpspst0103 <none> <none>
pod/elasticsearch-es-master-2 1/1 Terminating 0 6d5h 10.72.10.10 opkbwfpspst0101 <none> <none>
pod/kibana-kb-fccc88c7b-7rn84 1/1 Terminating 0 6d5h 10.72.9.135 opkbwfpspst0103 <none> <none>
pod/kibana-kb-fccc88c7b-mbst2 0/1 Running 29 (5m12s ago) 3h11m 10.72.6.233 opkbwfpspst0105 <none> <none>
pod/kibana-kb-fccc88c7b-wqtrh 1/1 Terminating 0 3h30m 10.72.3.225 opkbwfpspst0111 <none> <none>
pod/metricbeat-beat-metricbeat-6k48w 1/1 Running 3 (6d5h ago) 6d5h 192.168.114.110 opkbwfpspst0105 <none> <none>
pod/metricbeat-beat-metricbeat-h2btc 1/1 Running 3 (6d5h ago) 6d5h 192.168.114.108 opkbwfpspst0101 <none> <none>
pod/metricbeat-beat-metricbeat-hkvrh 1/1 Running 3 (6d5h ago) 6d5h 192.168.114.111 opkbwfpspst0107 <none> <none>
pod/metricbeat-beat-metricbeat-jz84w 1/1 Running 3 (6d5h ago) 6d5h 192.168.114.103 opkbmfpspst0103 <none> <none>
pod/metricbeat-beat-metricbeat-nrj8g 1/1 Running 3 (6d5h ago) 6d5h 192.168.114.112 opkbwfpspst0109 <none> <none>
pod/metricbeat-beat-metricbeat-qbf22 1/1 Running 3 (6d5h ago) 6d5h 192.168.114.113 opkbwfpspst0111 <none> <none>
pod/metricbeat-beat-metricbeat-qnf2b 1/1 Running 3 (6d5h ago) 6d5h 192.168.114.109 opkbwfpspst0103 <none> <none>
pod/metricbeat-beat-metricbeat-tmszg 1/1 Running 0 5d3h 192.168.114.102 opkbmfpspst0101 <none> <none>
pod/metricbeat-beat-metricbeat-v7474 1/1 Running 3 (6d5h ago) 6d5h 192.168.114.104 opkbmfpspst0105 <none> <none>
k get node
NAME STATUS ROLES AGE VERSION
opkbmfpspst0101 Ready control-plane 261d v1.24.1
opkbmfpspst0103 Ready control-plane 41d v1.24.1
opkbmfpspst0105 Ready control-plane 261d v1.24.1
opkbwfpspst0101 NotReady <none> 261d v1.24.1
opkbwfpspst0103 NotReady <none> 41d v1.24.1
opkbwfpspst0105 Ready <none> 261d v1.24.1
opkbwfpspst0107 Ready <none> 261d v1.24.1
opkbwfpspst0109 Ready <none> 261d v1.24.1
opkbwfpspst0111 NotReady <none> 261d v1.24.1
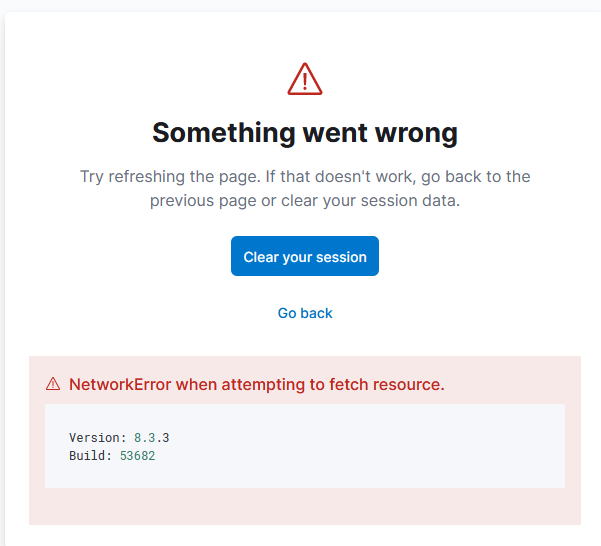
for kibana pods i have this logs and massage box in ui
Defaulted container "kibana" out of: kibana, elastic-internal-init-config (init)
[2022-09-19T14:28:21.165+00:00][INFO ][plugins-service] Plugin "cloudSecurityPosture" is disabled.
[2022-09-19T14:28:21.314+00:00][INFO ][http.server.Preboot] http server running at https://0.0.0.0:5601
[2022-09-19T14:28:21.370+00:00][INFO ][plugins-system.preboot] Setting up [1] plugins: [interactiveSetup]
[2022-09-19T14:28:21.422+00:00][WARN ][config.deprecation] The default mechanism for Reporting privileges will work differently in future versions, which will affect the behavior of this cluster. Set "xpack.reporting.roles.enabled" to "false" to adopt the future behavior before upgrading.
[2022-09-19T14:28:21.731+00:00][INFO ][plugins-system.standard] Setting up [118] plugins: [translations,monitoringCollection,licensing,globalSearch,globalSearchProviders,features,mapsEms,licenseApiGuard,usageCollection,taskManager,telemetryCollectionManager,telemetryCollectionXpack,share,embeddable,uiActionsEnhanced,screenshotMode,banners,newsfeed,fieldFormats,expressions,eventAnnotation,dataViews,charts,esUiShared,customIntegrations,home,searchprofiler,painlessLab,grokdebugger,management,advancedSettings,spaces,security,lists,encryptedSavedObjects,cloud,snapshotRestore,screenshotting,telemetry,licenseManagement,kibanaUsageCollection,eventLog,actions,console,bfetch,data,watcher,reporting,fileUpload,ingestPipelines,alerting,aiops,unifiedSearch,savedObjects,triggersActionsUi,transform,stackAlerts,ruleRegistry,graph,savedObjectsTagging,savedObjectsManagement,presentationUtil,expressionShape,expressionRevealImage,expressionRepeatImage,expressionMetric,expressionImage,controls,dataViewFieldEditor,visualizations,canvas,visTypeXy,visTypeVislib,visTypeVega,visTypeTimeseries,visTypeTimelion,visTypeTagcloud,visTypeTable,visTypeMetric,visTypeHeatmap,visTypeMarkdown,dashboard,dashboardEnhanced,expressionXY,expressionTagcloud,expressionPartitionVis,visTypePie,expressionMetricVis,expressionHeatmap,expressionGauge,visTypeGauge,sharedUX,discover,lens,maps,dataVisualizer,ml,cases,timelines,sessionView,observability,fleet,synthetics,osquery,securitySolution,infra,upgradeAssistant,monitoring,logstash,enterpriseSearch,apm,indexManagement,rollup,remoteClusters,crossClusterReplication,indexLifecycleManagement,discoverEnhanced,dataViewManagement]
[2022-09-19T14:28:21.753+00:00][INFO ][plugins.taskManager] TaskManager is identified by the Kibana UUID: 2de59019-bc41-4027-b05f-6fe55b440a3e
[2022-09-19T14:28:22.043+00:00][WARN ][plugins.reporting.config] Found 'server.host: "0.0.0.0"' in Kibana configuration. Reporting is not able to use this as the Kibana server hostname. To enable PNG/PDF Reporting to work, 'xpack.reporting.kibanaServer.hostname: localhost' is automatically set in the configuration. You can prevent this message by adding 'xpack.reporting.kibanaServer.hostname: localhost' in kibana.yml.
[2022-09-19T14:28:22.076+00:00][INFO ][plugins.ruleRegistry] Installing common resources shared between all indices
[2022-09-19T14:28:22.919+00:00][INFO ][plugins.screenshotting.config] Chromium sandbox provides an additional layer of protection, and is supported for Linux Ubuntu 20.04 OS. Automatically enabling Chromium sandbox.
[2022-09-19T14:28:23.717+00:00][INFO ][plugins.screenshotting.chromium] Browser executable: /usr/share/kibana/x-pack/plugins/screenshotting/chromium/headless_shell-linux_x64/headless_shell
[2022-09-19T14:30:23.072+00:00][FATAL][root] TimeoutError: Request timed out
at KibanaTransport.request (/usr/share/kibana/node_modules/@elastic/transport/lib/Transport.js:524:31)
at runMicrotasks (<anonymous>)
at processTicksAndRejections (node:internal/process/task_queues:96:5)
[2022-09-19T14:30:23.584+00:00][INFO ][plugins-system.preboot] Stopping all plugins.
[2022-09-19T14:30:23.585+00:00][INFO ][plugins-system.standard] Stopping all plugins.
[2022-09-19T14:30:23.588+00:00][INFO ][plugins.monitoring.monitoring.kibana-monitoring] Monitoring stats collection is stopped
FATAL TimeoutError: Request timed out
my manifest
apiVersion: beat.k8s.elastic.co/v1beta1
kind: Beat
metadata:
name: metricbeat
namespace: technical-bigdata-elk-d
spec:
type: metricbeat
version: 8.3.2
image: opkbhfpspsp0101.fns/efk/metricbeat:8.3.2
elasticsearchRef:
name: elasticsearch
kibanaRef:
name: kibana
config:
metricbeat:
autodiscover:
providers:
- hints:
default_config: {}
enabled: "true"
node: ${NODE_NAME}
type: kubernetes
modules:
- module: system
period: 10s
metricsets:
- cpu
- load
- memory
- network
- process
- process_summary
process:
include_top_n:
by_cpu: 5
by_memory: 5
processes:
- .*
- module: system
period: 1m
metricsets:
- filesystem
- fsstat
processors:
- drop_event:
when:
regexp:
system:
filesystem:
mount_point: ^/(sys|cgroup|proc|dev|etc|host|lib)($|/)
- module: kubernetes
period: 10s
node: ${NODE_NAME}
hosts:
- https://${NODE_NAME}:10250
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
ssl:
verification_mode: none
metricsets:
- node
- system
- pod
- container
- volume
processors:
- add_cloud_metadata: {}
- add_host_metadata: {}
daemonSet:
podTemplate:
spec:
serviceAccountName: metricbeat
automountServiceAccountToken: true # some older Beat versions are depending on this settings presence in k8s context
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
#value: master
effect: NoSchedule
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
containers:
- args:
- -e
- -c
- /etc/beat.yml
- -system.hostfs=/hostfs
name: metricbeat
volumeMounts:
- mountPath: /hostfs/sys/fs/cgroup
name: cgroup
- mountPath: /var/run/docker.sock
name: dockersock
- mountPath: /hostfs/proc
name: proc
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
dnsPolicy: ClusterFirstWithHostNet
hostNetwork: true # Allows to provide richer host metadata
securityContext:
runAsUser: 0
terminationGracePeriodSeconds: 30
volumes:
- hostPath:
path: /sys/fs/cgroup
name: cgroup
- hostPath:
path: /run/containerd/containerd.sock
name: dockersock
- hostPath:
path: /proc
name: proc
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: metricbeat
rules:
- apiGroups:
- ""
resources:
- nodes
- namespaces
- events
- pods
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- replicasets
verbs:
- get
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
- deployments
- replicasets
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/stats
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: metricbeat
namespace: technical-bigdata-elk-d
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: metricbeat
subjects:
- kind: ServiceAccount
name: metricbeat
namespace: default
roleRef:
kind: ClusterRole
name: metricbeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: elasticsearch
namespace: technical-bigdata-elk-d
spec:
version: 8.3.3
image: opkbhfpspsp0101.fns/efk/elasticsearch:8.3.3
volumeClaimDeletePolicy: DeleteOnScaledownOnly
nodeSets:
- name: master
count: 3
volumeClaimTemplates:
- metadata:
name: elasticsearch-data # Do not change this name unless you set up a volume mount for the data path.
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: ceph-rbd
config:
node.roles: ["master", "remote_cluster_client"]
xpack.ml.enabled: true
node.attr.attr_name: attr_value
node.store.allow_mmap: false
podTemplate:
spec:
containers:
- name: elasticsearch
resources:
requests:
memory: 2Gi
cpu: 2
limits:
memory: 2Gi
cpu: 2
#env:
# - name: ES_JAVA_OPTS
# value: "-Xms4g -Xmx4g"
readinessProbe:
exec:
command:
- bash
- -c
- /mnt/elastic-internal/scripts/readiness-probe-script.sh
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 12
successThreshold: 1
timeoutSeconds: 12
env:
- name: READINESS_PROBE_TIMEOUT
value: "10"
- name: data
count: 3
volumeClaimTemplates:
- metadata:
name: elasticsearch-data # Do not change this name unless you set up a volume mount for the data path.
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: ceph-rbd
config:
node.roles: ["data", "ingest", "ml", "transform"]
node.attr.attr_name: attr_value
node.store.allow_mmap: false
podTemplate:
spec:
containers:
- name: elasticsearch
resources:
requests:
memory: 2Gi
cpu: 2
limits:
memory: 2Gi
cpu: 2
#env:
# - name: ES_JAVA_OPTS
# value: "-Xms4g -Xmx4g"
readinessProbe:
exec:
command:
- bash
- -c
- /mnt/elastic-internal/scripts/readiness-probe-script.sh
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 12
successThreshold: 1
timeoutSeconds: 12
env:
- name: READINESS_PROBE_TIMEOUT
value: "10"
---
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: kibana
namespace: technical-bigdata-elk-d
spec:
version: 8.3.3
image: opkbhfpspsp0101.fns/efk/kibana:8.3.3
count: 1
elasticsearchRef:
name: elasticsearch
podTemplate:
spec:
containers:
- name: kibana
resources:
requests:
memory: 1Gi
cpu: 0.5
limits:
memory: 2.5Gi
cpu: 2
...
Is there a way to solve this problem?