@val Personally (other may have different opinions) I have never been a fan of the 1GB master, I have run into other issues with it. Are all your masters 1 GB? In Prod I tell my customer 4GB or 8 GB, (again only my preference) and yes there is a cost, but sometimes seems to help / provide headroom when there are master intensive tasks. Not saying this should not get fixed, just an opinion / experience.


Yup / Good... and that is quite a spike!
Yes, I have different opinions...
The point is that there shouldn't be such a thing as a "master intensive task", it really should just be possible to size the masters as if they just look after the cluster state. The elected master is an irreducible bottleneck anyway, the less we depend on it the better our lives become. If you come across any other cases like this, please report them rather than just deploying 4x oversized masters.
Yes, as I said, me too. Circuit-breakers are pretty crude, I think there's scope to do something less drastic, but I'll leave these questions in the hands of the folk that will do the work.
Unfortunately, it seems Elastic Cloud doesn't allow to change the enrich.fetch_size setting and it's also not listed in the allowed settings.
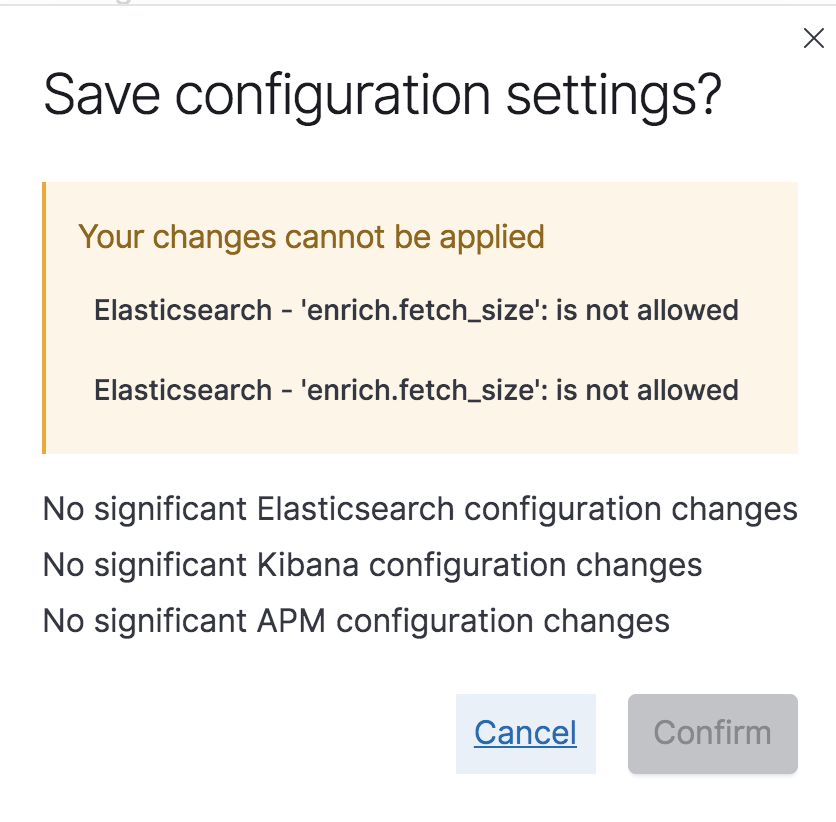
Groan. Of course you can't.
I believe your support engineer will have the power to change it.
Once I hear from him 
Our support engineer was able to change enrich.fetch_size to 5000 and that allowed us to execute the policy.
So that unblocks us for now but I'm still eager to know once there is a more durable fix.
I opened an issue on Github to report this as a bug:
Thanks, I was supposed to do it, but that fell through the cracks, sorry 