Hello
Appreciate this topic has lots of topics already, but I have a few specific (but general) questions;
Use case:
Web logs, cron logs, other logs into an elastic stack so devs can look at logs, spot problems etc.
100% availability not required, but would be annoying to reindex all the logs again from scratch.
Sort of unrelated - also want somewhere to run jenkins and tests
Current situation
1 Machine running full elastic stack (elastic/kibana/logstash) & Jenkins, selenium and some other tools.
Jenkins is slow when elastic is doing stuff, and visa versa, so everything is just generally slow 
I have 4 indexes, all now setup as 1 shard (and one replia), for a daily period. (might change this to weekly for some indexes as each shard doesn't hold much data (50mb).
Proposal
As this is just for internal dev, don't have a super huge budget 
I am thinking about setting up 2 machines, like the pretty picture on the add failover guide
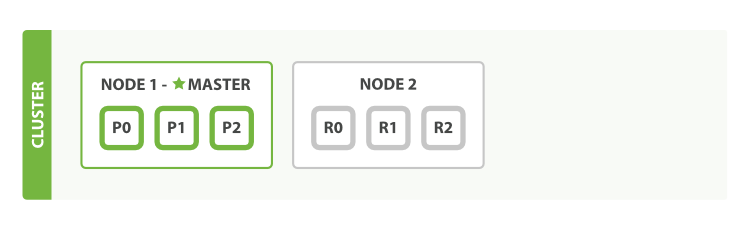
Machine 1
- elastic master & data
- kibana
- logstash
- jenkins slave
Machine 2
- elastic data (replica)
- jenkins master
- other testing tools
Fully appreciate it is not recommended to run a 2 node elastic cluster, but can't really justify another machine just to make elastic happy, so;
1 master to stop split brain situation. We're not too fussed if master dies for a little bit, so long as we can get it back manually in a 'reasonable' amount of time
Question 1:
Say machine 1 blows up. Can I do the following, and will it work as I think it will?
I promote machine 2 to a master temporarily (replica shard happy to turn into primaries?), then setup a new machine 1 as a data only node. Data is then replicated across. I then stop machine 2, make machine 1 a master, reset machine 2 back to data only. Everyone is happy, machine 1 is master, machine 2 is data replica and don't have to reindex all logs?
Question 2:
Kibana - I set this to talk to machine 1. Will elastic on machine 1 work out that there is a data node it can talk to as so share out some of the work?
Question 3:
Rolling upgrades - I just upgrade master as per docs, then data only. Everything happy?
Full cluster restart - I stop master and data, upgrade master, then data. Everything happy?
Many thanks!
