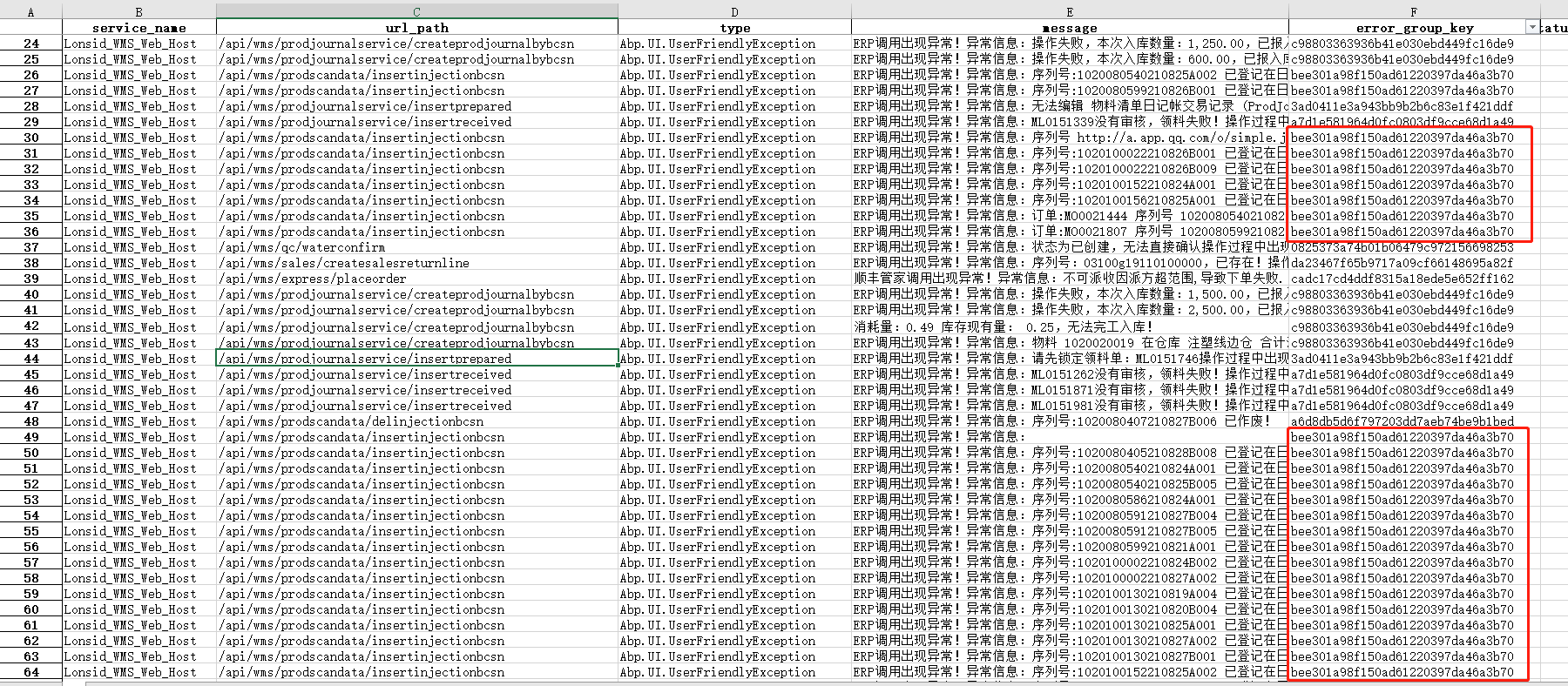
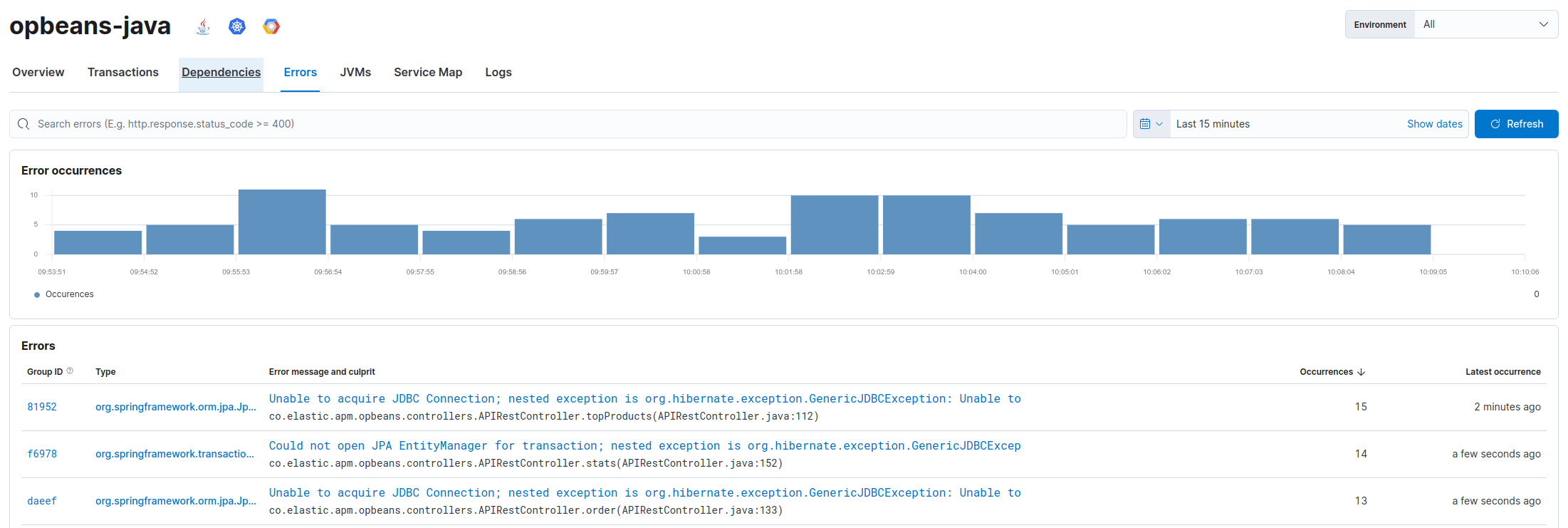
When service.name, url_path, and type are the same, why sometimes the id is the same, sometimes not the same id
I want to know the error_group_id calculated according to what formula?
Each row corresponds to a unique error.grouping_key value. Occurrences counts how many errors have the same grouping key value, and Last occurrence shows the time since the most recent error with that grouping key value.
Thank you for your reply, what you mean is similar to what I expected, but why in the third picture, the same service.name, url_path, type, message will generate multiple error_group_id?
The grouping key will change if the exception stack trace is different, even if the message and exception type are the same. Maybe the exception is being thrown in two different code locations?
I am a little bit understanding
Maybe the exception is being thrown in two different code locations?
If an exception is thrown in two code locations, why is the same error? For example, A function calls B function and C function calls B function. If an error occurs, is APM recorded as the code location of B function?
Sorry, I may not be able to describe it clearly.
If an exception is thrown in two code locations, why is the same error? For example, A function calls B function and C function calls B function. If an error occurs, is APM recorded as the code location of B function?
They should have different grouping keys in this case. The grouping key calculates a hash of the full stack trace: e.g. if A calls B, then the grouping key will include details of both A and B.
If a is called, it will call c and panic. The grouping key is a hash of "a" and "c"
If b is called, it will call c and panic. The grouping key is a hash of "b" and "c"
So they will be different, because even though the error occurs in c, the stack trace is different -- the code took a different path to get there. But each time a is called, it will have the same grouping key as every other time a is called.
I can only guess that the same exception is occurring in several different stack traces. You can confirm this by selecting error documents with different error.grouping_key values, and comparing their error.exception.stacktrace fields. If they are different, then that would explain why they have different grouping key values.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.