After encountering significant performance issues and memory leaks with Filebeat when processing high volumes of logs, especially with the Fortinet module enabled, I made several configuration changes to address the bottleneck caused by the in-memory queue.
The root cause seemed to be that events were being processed too slowly, regardless of the worker or other settings, leading to a backlog in the memory queue. To alleviate this, I switched to using the disk-based queue (queue.disk) instead of the in-memory queue (queue.mem). This change alone didn't provide a complete solution, but it did improve the throughput.
The problem with the memory queue was that events were flushed too slowly, irrespective of the worker configuration or other settings. Changing the values of output.elasticsearch.worker (5/10/20/40/100) had an unpredictable effect on performance. Increasing the number of workers did not significantly improve the results. This raises the question of whether the worker thread performance was limited by the number of CPU cores or threads available.
Reducing the queue.flush.timeout to 10ms(0/1/100) provided better results but did not ensure queue stability, as the queue size continued to grow(but slower with some configurations). Ultimately, switching to the disk-based queue resolved the problem.
After all the testes i got this:
output.elasticsearch:
...
worker: 40
bulk_max_size: 10000
compression_level: 2
queue.disk:
max_size: 15GB
Filebeat stopped consuming excessive amounts of memory. While it still consumes some memory, it no longer queues events in RAM and gets overwhelmed during log surges or restarts. Now, when there are more events to process, they are handled more efficiently using the disk-based queue.
With these changes, I observed the following improvements:
- Filebeat's memory consumption stabilized, although it still uses some memory, but it no longer causes a memory leak.
- The number of logs processed increased by approximately 40%.
- Filebeat can now handle a stable peak throughput of 12,000 events/second(i guess if iops will be not a problem it should get to 30k/s on this 2 cpu 12 GB).
- CPU usage increased by around 20% on a 2-core CPU(stable 60% now).
- using filestream instead of input helped with stability
- The write iops skyrocketed(it is an issue i will further investigate)

Filebeat


Elasticsearch
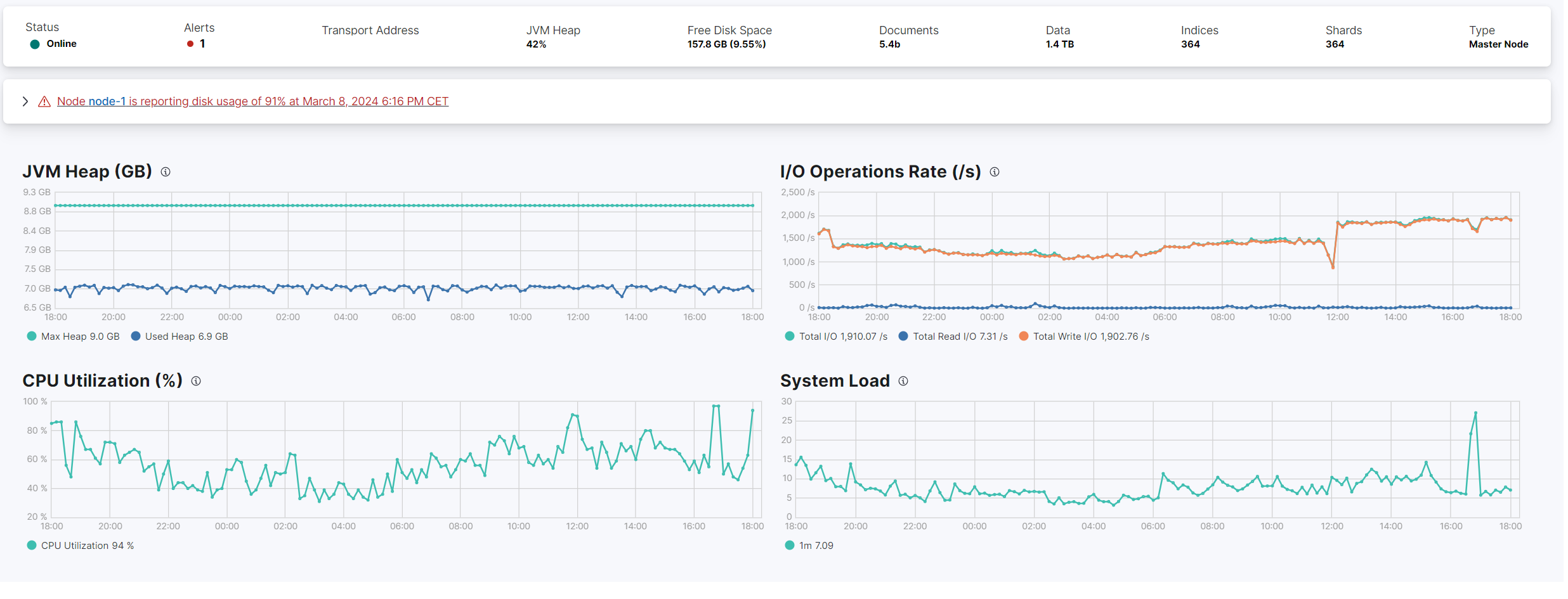

My remaining question is whether the number of processors and threads has any significance with this disk-based queue configuration, given the unpredictable effects observed when adjusting the worker thread count with the in-memory queue configuration?