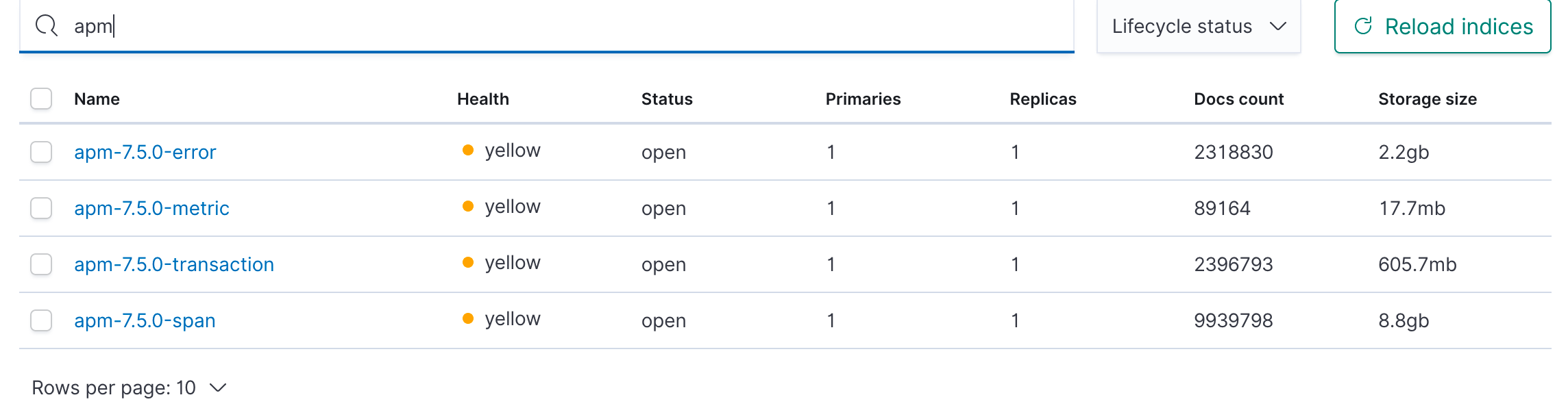
Kibana version:
7.5.0 Elasticsearch version:
7.5.0 APM Server version:
7.5.0
Original install method (e.g. download page, yum, deb, from source, etc.) and version:
ECK Manifest
Fresh install or upgraded from other version?
Fresh
Description of the problem including expected versus actual behavior. Please include screenshots (if relevant):
I am running ECK eck/eck-operator:1.0.0-beta1 and have a elastic/apm/kibana stack setup across approximately 30 clusters.
On some of these everything seems to be working fine:
and I start seeing illegal_argument_exception: index.lifecycle.rollover_alias [apm-7.5.0-error] does not point to index [apm-7.5.0-error] in kibana
and the following in the apm server logs:
2019-12-19T02:49:56.716Z ERROR pipeline/output.go:100 Failed to connect to backoff(elasticsearch(https://monitoring-es-http.client-env-monitoring.svc:9200)): Connection marked as failed because the onConnect callback failed: resource 'apm-7.5.0-error' exists, but it is not an alias
2019-12-19T02:49:56.716Z INFO pipeline/output.go:93 Attempting to reconnect to backoff(elasticsearch(https://monitoring-es-http.client-env-monitoring.svc:9200)) with 3734 reconnect attempt(s)
I'm assuming these aliases should be getting creating but I am not completely sure on that so I guess that's my first question, do I need to create these aliases manually? If not, I could use a bit of direction in figuring out what is going on.
Hi @jmcpherson,
the aliases are automatically created when the APM Server is started and ILM is enabled (which is the default in 7.5 if you haven't manually configured any output.elasticsearch.index settings).
Can you give some more information: have you upgraded the deployment from a former version or is it a fresh installation, and have you made any config changes related to ILM, output or template setup?
Some of the clusters have been updated from 7.2. During the update process I mistakenly updated all components at the same time and ended up deleting all indexes on all clusters to fix the deployment. I have tried deleting the indexes and letting apm recreate them, in a couple instances that has worked, but it’s not consistent. I have made no changes to the configuration.
That manual interaction explains the issues. I can reproduce the behavior when deleting indices while ingesting data.
The APM Server creates the alias and everything necessary for ILM on startup. When the alias is manually deleted though while the APM Server is running, it will further ingest the data and an index with the same name as the deleted alias will be dynamically created by Elasticsearch, leading to an invalid state.
The easiest way to resolve this issue would probably be to spin up new ECK clusters or to stop sending data to the problematic instances, delete the created indices, start APM Server again and ensure aliases, templates and policies are created properly before starting to send data again.
If this is not feasible, you could also think about something like
(1) stop the ingestion to the problematic indices and mark them read-only
(2) clone the indices using a new non-conflicting name
(3) delete the old index
(4) create alias and ILM setup again via starting the APM Server
(5) start data ingestion
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.