I've been having an issue where my one client node just deletes the primary index.. I'm basically discussing it with myself here, as no one has really offered much help.
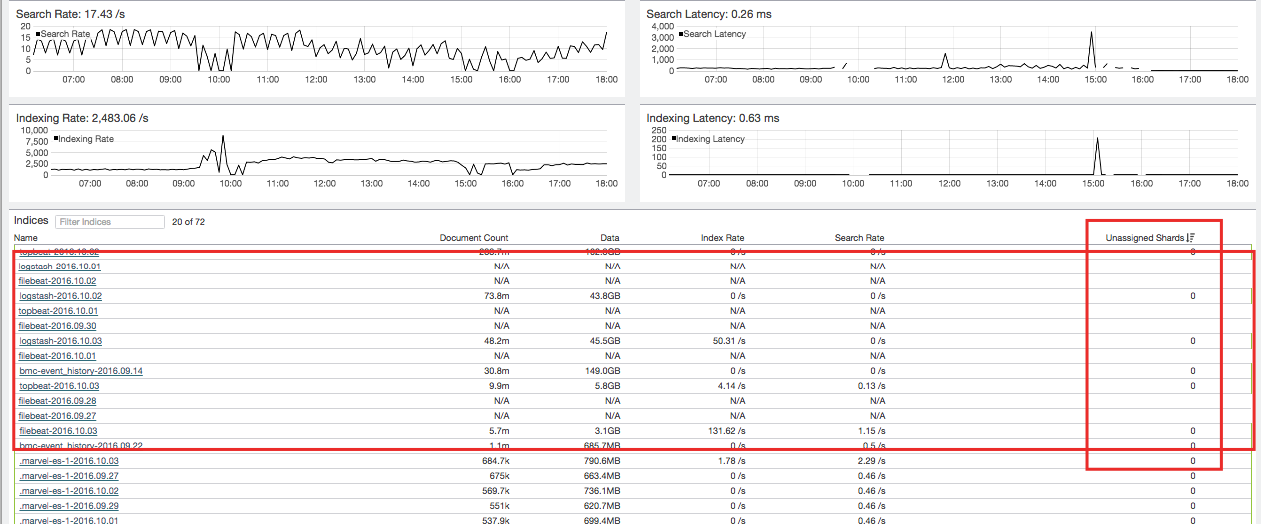
Now I'm in a position where my cluster state has been 'Red' for hours due to these nonexistent shards. As seen in this Filebeat index, there are no shards available, yet it still wants to think that the index there.
I look for unassigned shards and find absolutely nothing, it doesn't even say '0' shards.
It looks like this all happened almost exactly at 16:00. I wonder if you all are using a Curator job to delete indices? If so, it's possible that one of the data nodes was not around when that occurred, so it rejoined with "dangling indices" and caused the master to think that it's missing shards when in fact it should just delete those too.
Later, it would be reasonable that Curator would run a second time and delete the dangling shards, which fixed the problem.
Having said that, I noticed the screenshot is showing dates that are probably too soon to be deleted by Curator, so I'll take a gander at the linked discussion and see what's going on over there.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.