{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "cannot create index with name [logs-carbon_black.observations-default-2025.02.09-000002], because it matches with template [logs] that creates data streams only, use create data stream api instead"
}
],
"type": "illegal_argument_exception",
"reason": "cannot create index with name [logs-carbon_black.observations-default-2025.02.09-000002], because it matches with template [logs] that creates data streams only, use create data stream api instead"
},
"status": 400
}
There’s an existing template / data streaming (fancy name for an alias to multiple indices, don’t shoot me for being imprecise), maybe that’s as it came with the system.
Your index name matches, so you cannot use it really.
You cannot change the index.default_pipeline nor the index.final_pipeline for any Elastic Agent integration.
All customizations needs to be done in the @custom ingest pipeline for the specific dataset of the integration or globally in the logs@custom ingest pipeline.
I mean that is a pretty unusual “notation”, right. Is there some significance? Is 78,258,031 a shorthand for what is more usually written as 78.258.31.0/24? It’s a convention in a particular country/language/field ?
Yeah you are right. I maybe should fix this directly in my code where I do my API call with python.
The output was actually in hexa, so Elastic though it was int.
So this code fixed it.
if 'netconn_ipv4' in json_data:
json_data['netconn_ipv4'] = int_to_ip(json_data['netconn_ipv4'])
if 'netconn_local_ipv4' in json_data:
json_data['netconn_local_ipv4'] = int_to_ip(json_data['netconn_local_ipv4'])
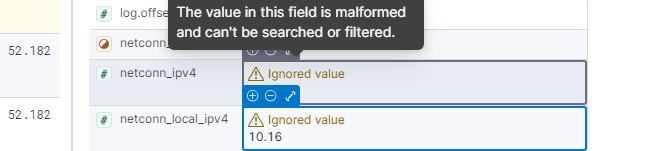
As you can see type is number not IP
So you have still not set the mapping correct And or there is a conflict in the data view? Because you have two indices with two different types of mappings this can cause these kind of issues
When we were working together, the script cp.py produced output from two fields (netconn_ipv4 and netconn_local_ipv4) in hexadecimal format. In Elasticsearch, these fields were interpreted as integers. I modified cp.py to convert the hexadecimal values to IP addresses.
I haven't changed the pipelines, and I don't need to re-index since it's not in production yet. Now, I simply want these fields to be recognized as IP addresses and nothing else. Custom logs and parsing in Elasticsearch can be challenging, and it seems I'm not alone in this struggle if you search online. I apologize if my explanation isn't clear enough.
Ok that helps. Remember, we are answering many questions... following each topic "Train of thought" can be challenging
Yes, it can... and there is a framework that can take a little getting used to ... and making assumption about how it works without reading the docs can sometimes make it worse, or using some other article etc...
Ok good delete the existing data stream...
That will clean everything up.
Then start your data flow again... and report back.
The result of this will give us 1 of 2 path to follow.
It will work because you no longer have conflicting mappings in the data view (pretty sure this is the case)
We will add a custom mapping for those 2 fields (which is simple I will show you) and then we will clean up and start again.
For # 2 adding the custom mapping is simply this but test first and come back. This will force the 2 fields to be of the correct type
Could help others if you could provide a couple of bullets on your end solutions, then we will marked as solved ... that will help others in the community.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.