Hi All,
I'm curious if anyone has any ideas on an issue I'm seeing.
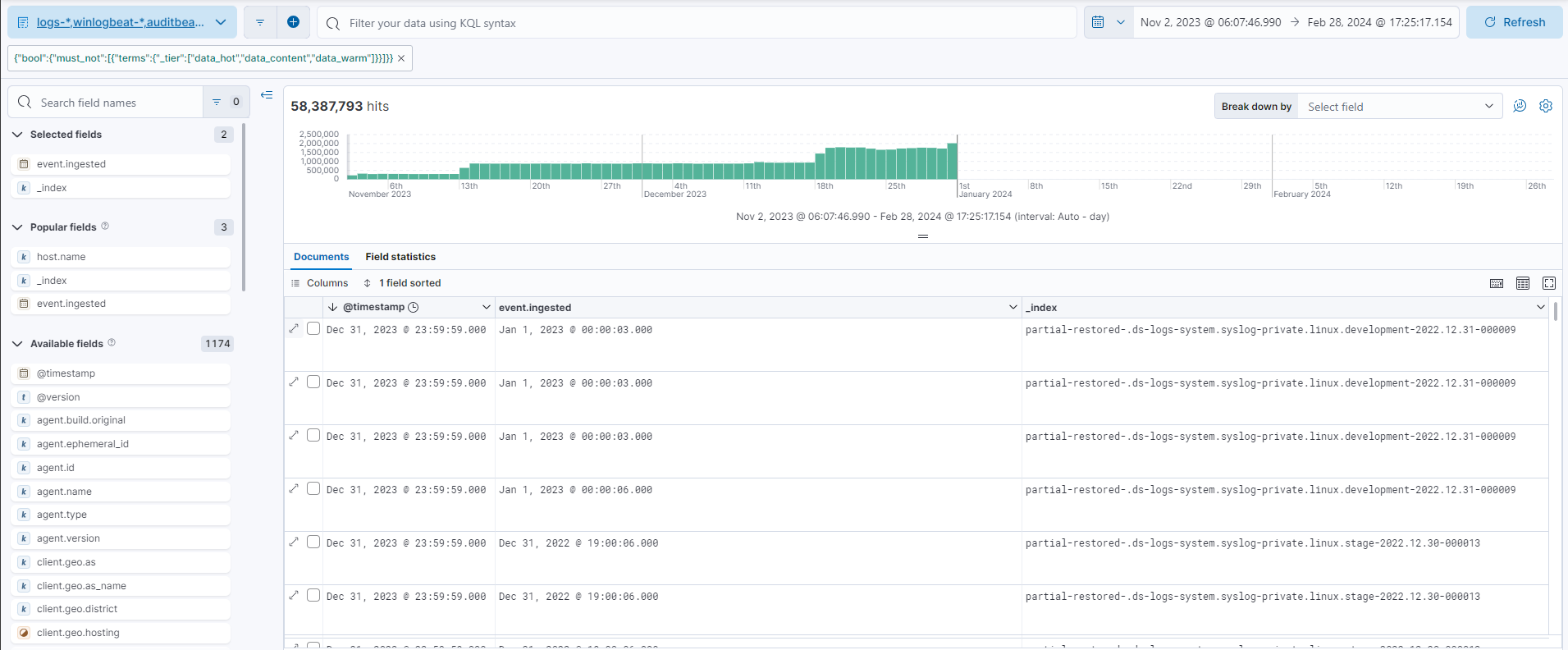
I have a cluster of 33 nodes, 3 of these nodes are coordinating only nodes that handle all requests.
I've been noticing that these coordinating nodes have an extremely high parent circuit breaker tripped count.
"uUIbozFjSMOm1CKZlB5Atg": {
"name": "es-prod-es-rack1-coord-0",
"breakers": {
"parent": {
"tripped": 119819
}
}
},
"ATktQgbSTSWWuV1oJpJnRg": {
"name": "es-prod-es-rack2-coord-0",
"breakers": {
"parent": {
"tripped": 49858
}
}
},
"aMKjx9cSSbe67xzTOv8wVw": {
"name": "es-prod-es-rack5-coord-0",
"breakers": {
"parent": {
"tripped": 41976
}
}
},
For reference of the other 30 nodes in the cluster only 2 other nodes have more than 0 trips and they're both relatively low:
"ewLOLe_LTxe-MWS3REVtNQ": {
"name": "es-prod-es-rack5-data-hot-0",
"breakers": {
"parent": {
"tripped": 8465
}
}
},
"NKuwIgtERMe_1KaLBTAGUQ": {
"name": "es-prod-es-rack2-data-warm-0",
"breakers": {
"parent": {
"tripped": 259
}
}
},
The coordinating only nodes have the following specs:
- Min: 10 "CPU", Max: 14 "CPU"
- Memory: 24Gi
- Heap: 22g
ES_JAVA_OPTS: -Xms22g -Xmx22g
The entire cluster is on 8.9.2.
The cluster processes ~35k e/s (70 e/s including replicas), and handles ~1k search/s (lows) - 7k search/s (peaks).
Most of the events are from Elastic Agents, and most of the searches are from Kibana rules (Observability/Security).
Looking at the monitoring of the Coordinating nodes, I see heap is generally around 13-14G with peaks ~18-19G.
I'm curious if anyone has any ideas on dealing with these circuit breakers. I did read Circuit breaker errors | Elasticsearch Guide [8.10] | Elastic & Circuit breaker settings | Elasticsearch Guide [8.10] | Elastic, but there isn't clear guidance on how to track down what the main "consumers" of parent are.
I did also take a look at the 8.10.x release notes to see if there were any things that might show an improvement here.
Note: I'm posting this because it almost feels like a bug/regression from the last few releases ?~8.7.x? (I don't have proof that this is a regression, but I think I see the circuit breaker more now, and the cluster load hasn't changed much).