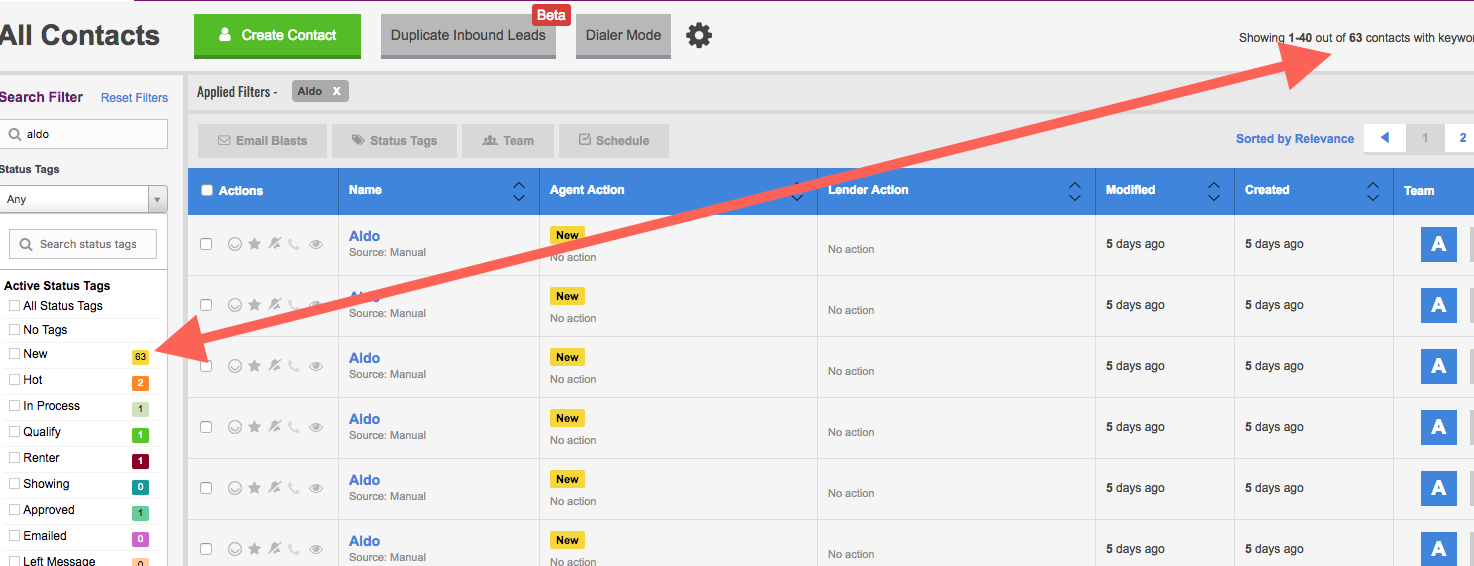
As can be seen in the screenshot, our app has counts for tagged contacts. The arrow above shows that there are 63 contacts that have the "New" tag.
These are stored as keywords on each contact, currently, and we're doing an aggregate query to pull the counts of all contacts that have said tags.
{
"size":0,
"aggs":{
"tag_names":{
"terms":{
"field":"tag_names",
"size":1000
}
}
},
"query":{
"bool":{
"filter":[
{
"terms":{
"permissions_cache":{
"index":"bpd-development",
"type":"resources_memberships",
"id":4,
"path":"user_memberships"
}
}
}
]
}
}
}
Clients will 100% notice if these counts are off, especially for "New", since that's what they look at every day to make sure they're not wasting fresh leads.
This is a SaaS based product and visibility of contacts is based off of permissions. The permissions can be very tricky since there are several different layers of access control that can be granted at any point in time. As such, recalculating peoples' counts based off of changing permissions would be quite unfeasible.
So... is there any way that I can get accurate counts without having to keep an actual counter somewhere?
If the total number of unique tags in your system is less than 1,000 then results for your query should be accurate since you asked to consider the top 1,000 values.
It's only if you have say a million tags in a sharded index that the counts for the top 1,000 may be off in results.
The total number of unique tags in the system is in fact in the millions because this is a SaaS product. However, users will typically have no more than a couple hundred uniq "accessible" tags. That's why the permissions_cache filter thing is there.
Will this change anything?
here is an example record:
{
"_index" : "bpd-development",
"_type" : "contact",
"_id" : "71",
"_version" : 2,
"found" : true,
"_source" : {
"contact_id" : 71,
"id" : 71,
"company_id" : 2,
"first_name" : "Aldo",
"created_at" : "1499925395000",
"updated_at" : "1500424806000",
"last_name" : null,
"first_name_exact" : "aldo",
"last_name_exact" : "",
"source_name" : null,
"lead_source_id" : null,
"agent_redistribution_status" : "assigned",
"lender_redistribution_status" : "assigned",
"last_lender_history_date" : null,
"last_agent_history_date" : null,
"last_lender_history_id" : null,
"last_agent_history_id" : 401,
"starred_by" : [ ],
"contact_types_contacts" : [ ],
"contact_statuses_contacts" : [
"31"
],
"permissions_cache" : [
"3",
"4",
"6",
"7",
"12"
],
"permissions_cache_length" : 5,
"metadata" : "asdfasdfsadf asdf asfas fsad fsd aldo"
}
}
It's all about the size of the set that each shard brings back to the "reducer node" vs the size of the set that match the query.
If a shard's results represent a subset of all the accessible tags collected in a query then that means some information is left behind and some lower-scoring tags from that shard will be omitted in the final analysis (popular tags are still likely to be accurate).
If your individual users each have a set of <1,000 tags all should still be well. If a user has a massive number of tags then there is the potential for error but we tell you about this in the search results. Use this feedback to figure out if you have a problem or not before we talk about potential solutions.