I am looking for ways to de-normalize elastic search indexes.
Input Test Data
Dept table

Location Table

Expected Denormalized table
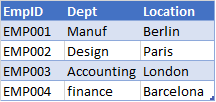
One way to de-normalize is to de-normalize the data before ingesting the data to Elasticsearch.
However, I am looking for a way to de-normalize the data within elastic search either through Painless or Groovy scripting. I hope this way will be more efficient.
Any help with sample script would be highly appreciated.
Input Dept Table
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1,
"hits": [
{
"_index": "dept",
"_type": "doc",
"_id": "0FsU4GYB7KWFLJIK6BFJ",
"_score": 1,
"_source": {
"empid": "EMP001",
"dept": "Manuf"
}
},
{
"_index": "dept",
"_type": "doc",
"_id": "0VsU4GYB7KWFLJIK6BFJ",
"_score": 1,
"_source": {
"empid": "EMP002",
"dept": "Design"
}
},
{
"_index": "dept",
"_type": "doc",
"_id": "01sU4GYB7KWFLJIK7BG3",
"_score": 1,
"_source": {
"empid": "EMP004",
"dept": "finance"
}
},
{
"_index": "dept",
"_type": "doc",
"_id": "0lsU4GYB7KWFLJIK6BFJ",
"_score": 1,
"_source": {
"empid": "EMP003",
"dept": "Accounting"
}
}
]
}
}
Input Location Table
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1,
"hits": [
{
"_index": "location",
"_type": "doc",
"_id": "mVsi4GYB7KWFLJIKMxiO",
"_score": 1,
"_source": {
"empid": "EMP001",
"location": "Berlin"
}
},
{
"_index": "location",
"_type": "doc",
"_id": "m1si4GYB7KWFLJIKOBgv",
"_score": 1,
"_source": {
"empid": "EMP003",
"location": "London"
}
},
{
"_index": "location",
"_type": "doc",
"_id": "mFsi4GYB7KWFLJIKMxiO",
"_score": 1,
"_source": {
"empid": "EMP002",
"location": "Paris"
}
},
{
"_index": "location",
"_type": "doc",
"_id": "mlsi4GYB7KWFLJIKMxiO",
"_score": 1,
"_source": {
"empid": "EMP004",
"location": "Barcelona"
}
}
]
}
}
Expected denormalized data
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1,
"hits": [
{
"_index": "denormalized",
"_type": "doc",
"_id": "G1sp4GYB7KWFLJIKCBz8",
"_score": 1,
"_source": {
"empid": "EMP001",
"location": "Berlin",
"dept": "Manuf"
}
},
{
"_index": "denormalized",
"_type": "doc",
"_id": "HVsp4GYB7KWFLJIKDhyn",
"_score": 1,
"_source": {
"empid": "EMP004",
"location": "Barcelona",
"dept": "finance"
}
},
{
"_index": "denormalized",
"_type": "doc",
"_id": "HFsp4GYB7KWFLJIKCBz8",
"_score": 1,
"_source": {
"empid": "EMP003",
"location": "London",
"dept": "Accounting"
}
},
{
"_index": "denormalized",
"_type": "doc",
"_id": "Glsp4GYB7KWFLJIKCBz8",
"_score": 1,
"_source": {
"empid": "EMP002",
"location": "Paris",
"dept": "Design"
}
}
]
}
}