My refresh rate is at 10s, I have it configured in an template. I increased it before in order to help with this issue, maybe I can increase it more.
In my configurations I don't explicitly set a queue, but as I understand, the default is an in memory queue:

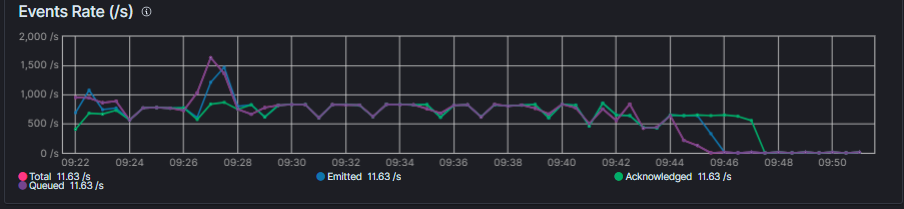
My Logstashes don´t seem to be using all their resources either:
Regarding GC, we see a warining about it all the time, but after spending quite a while looking online for it I was never able to find some conclusive cause or fix. Specially considering that I was told several times, that for the amount of documents I´m ingesting, the resources I have are more than enough, maybe that is incorrect as well, see the memory graph and the logs:
> {"type": "server", "timestamp": "2020-07-23T11:05:53,438Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7366707] overhead, spent [328ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:06:05,484Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7366719] overhead, spent [281ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:10:52,967Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7367006] overhead, spent [261ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:11:13,981Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7367027] overhead, spent [250ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:12:15,086Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7367088] overhead, spent [272ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:18:42,537Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7367475] overhead, spent [258ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:19:03,579Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7367496] overhead, spent [292ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:19:23,607Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7367516] overhead, spent [254ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:20:25,730Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7367578] overhead, spent [255ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:28:55,680Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7368087] overhead, spent [276ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:33:04,049Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7368335] overhead, spent [288ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:38:23,693Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7368654] overhead, spent [262ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:39:35,840Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7368726] overhead, spent [292ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:42:21,277Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7368891] overhead, spent [260ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:45:30,724Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7369080] overhead, spent [272ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:46:42,840Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7369152] overhead, spent [281ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T11:46:53,862Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7369163] overhead, spent [262ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:00:03,567Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7369951] overhead, spent [281ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:04:54,188Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7370241] overhead, spent [264ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:05:36,324Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7370283] overhead, spent [274ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:06:17,437Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7370324] overhead, spent [263ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:12:43,241Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7370709] overhead, spent [265ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:13:04,272Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7370730] overhead, spent [263ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:18:33,978Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7371059] overhead, spent [322ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:26:23,285Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7371527] overhead, spent [252ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:31:03,810Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7371807] overhead, spent [295ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:31:24,843Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7371828] overhead, spent [308ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:34:47,362Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7372030] overhead, spent [327ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:34:51,374Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7372034] overhead, spent [286ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:35:07,592Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7372050] overhead, spent [252ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:35:43,887Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7372086] overhead, spent [274ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:36:27,164Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7372129] overhead, spent [405ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }
> {"type": "server", "timestamp": "2020-07-23T12:40:25,387Z", "level": "INFO", "component": "o.e.m.j.JvmGcMonitorService", "cluster.name": "docker-cluster", "node.name": "elasticsearch2", "message": "[gc][7372365] overhead, spent [269ms] collecting in the last [1s]", "cluster.uuid": "69cIMsbUTUOiK3MOdNggow", "node.id": "25AFdrnqTG6lRsDR4CxZpQ" }









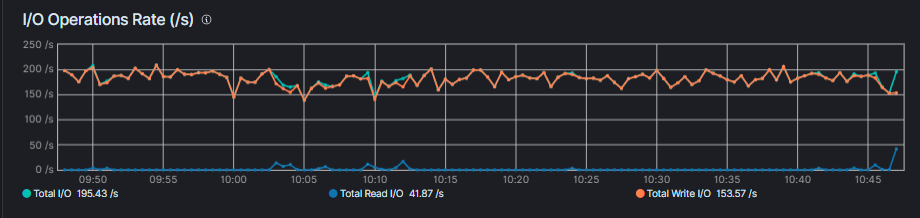



 though if SSD no faster, that's odd as should be big difference if disks are issue.
though if SSD no faster, that's odd as should be big difference if disks are issue.