Hi for all my clusters I see the direct correlation between pending tasks and GC time.
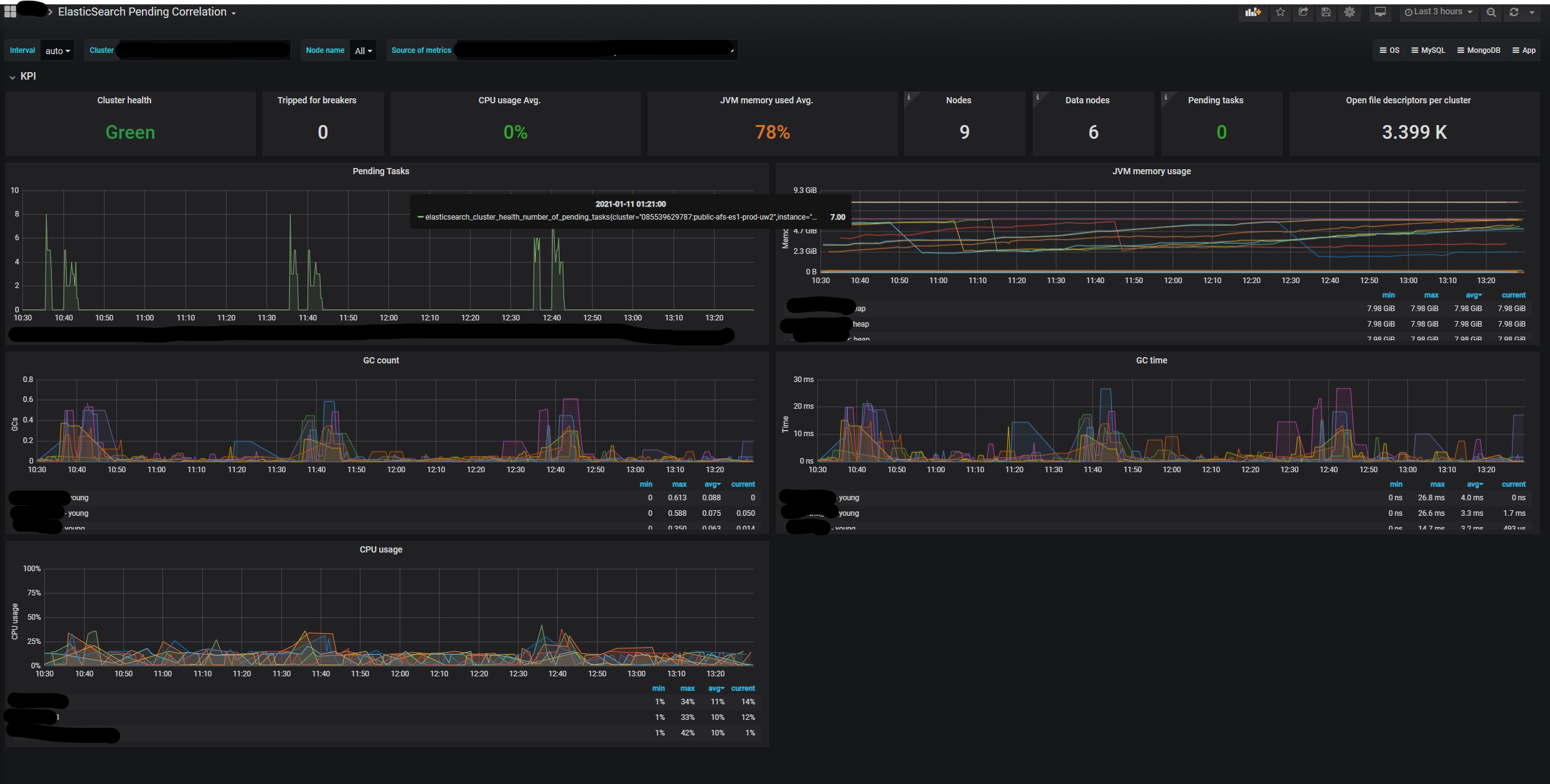
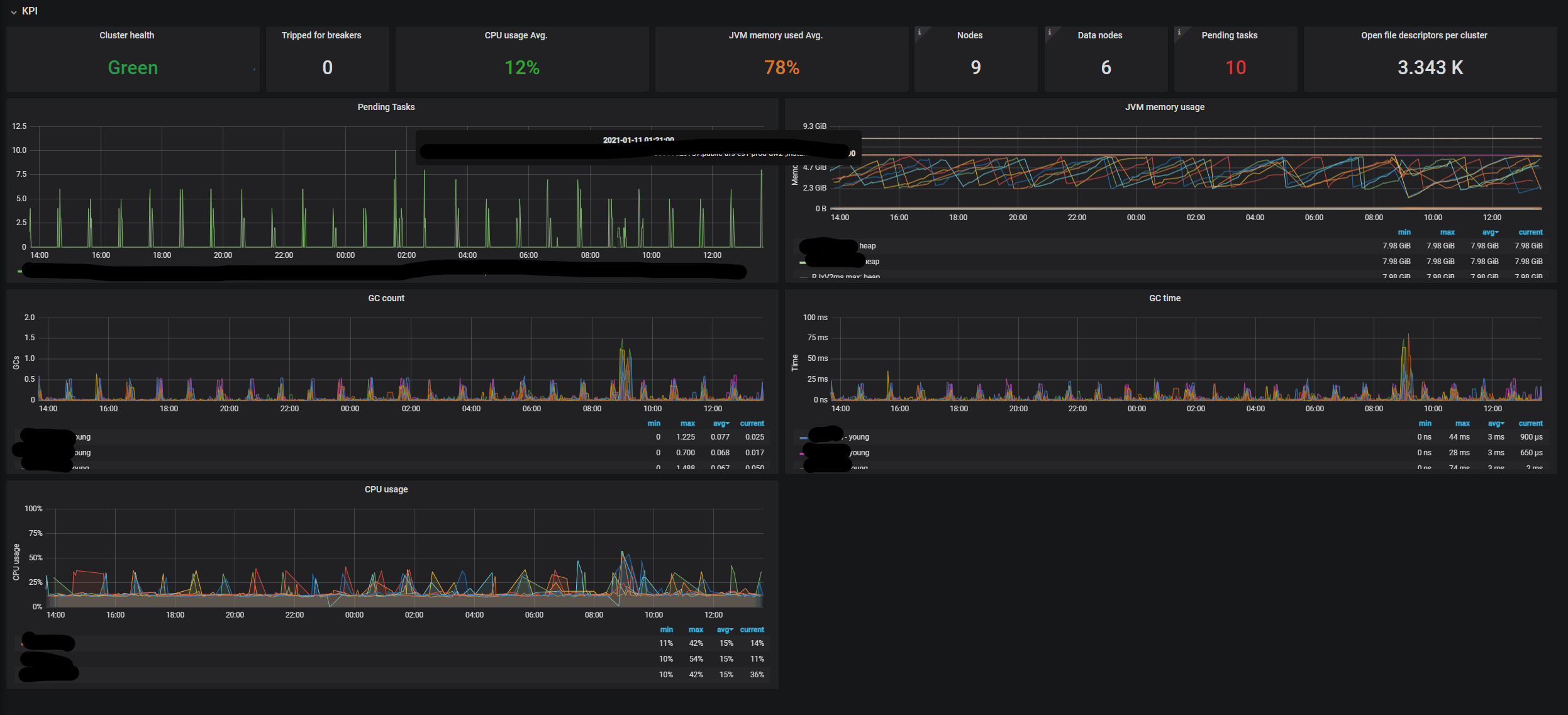
What can I do with that? How can avoid this situation?
Most of the pending tasks are snapshot related. We are decided to disable snapshots.
Snapshots are the last line of defence against data loss so its important to use them.
What's the actual issue here? A few ms of GC every 30 minutes or so doesn't sound like a problem that needs solving, and disabling snapshots will cause pain in future.
Snapshots aren't mandatory for us. We can easily restore data. The main problem, that our application stop writes to elastic search when we have pending tasks. In this situation, we have to "freeze" work to 5 minutes every hour and it isn't acceptable.
Pending tasks are processed on the master and are therefore always a bottleneck since there's only ever one master. If you are performance-sensitive then you should definitely avoid having master-related actions on your indexing pathway - this mainly means dynamic index creation and dynamic mapping updates.
I also don't see how a few ms of GC translates into a five-minute "freeze", that's definitely not normal.
There are minutes when GC works (spikes on the graphs). During this time you can see pending tasks spike. Our current solution stops write the data to the elastic if sees that we have pending tasks. From the elastic side, I suppose data will proceed. But we overloaded it in the past, so we decided to make the current solution as you see. I'm not sure that it was the right solution.
Ok, that makes more sense. Don't do that. You absolutely can carry on indexing whether the master is busy or not.
© 2020. All Rights Reserved - Elasticsearch
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant logo are trademarks of the Apache Software Foundation in the United States and/or other countries.