We are running Magneto 2.4 using Elastic hosted on Elastic.co.
Elastic Cloud version 7.17 due to Magento 2.4 requirements.
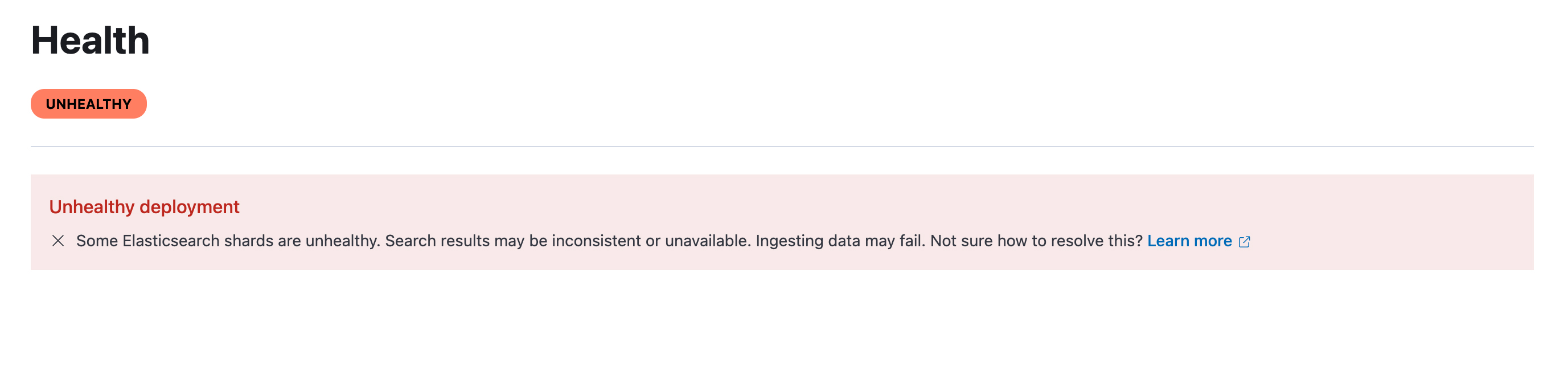
Recently our Elastic Cloud is showing "Unhealthy" but all zones are "Healthy" - screenshot attached.
Magento 2 logs are showing the occasional error, one every day or two:
[2023-03-10 09:26:05] main.ERROR: Bulk index operation failed 1 times in index magento2_default_tracking_log_session_20220507 for type _doc. Error (unavailable_shards_exception) : [magento2_default_tracking_log_session_20220507][0] primary shard is not active Timeout: [1m], request: [BulkShardRequest [[magento2_default_tracking_log_session_20220507][0]] containing [index {[magento2_default_tracking_log_session_20220507][_doc][null], source[{"session_id":"null","category_view":[9,32],"visitor_id":["null"],"product_view":[7,481,125,359,363,31,38,48,144,163,197,213,254,260,316],"end_date":"2023-03-10 09:24:44","start_date":"2022-05-07 08:27:25","store_id":1}]}]]. Failed doc ids sample : null. [] []
Can anyone assist with the cause of this error and how it can be resolved? The Health tab in the Elastic Cloud doesn't show any details.
Thanks Stephen, I have read through that document.
To my understanding the first step may be to resolve the "primary shard is not active Timeout: [1m]" error?
Are you able to point me in the right direction, does this sound like an issue with our Elastic Cloud setup, or Magento setup?
The setup has been working for 12+ months without issue and this started around 2 weeks ago. We're hosting Magento on an AWS EC2 using an AWS RDS database.
You should run the commands on this page the documents are pretty clear on how to analyze and bring us back the results.
Especially the explain... That That is how you're going to figure this out why your primary shard is missing.
Run those commands and bring back the results...
I cannot say for sure, but I suspect this is not an elastic cloud issue. You're nodes are green and there's plenty of room on the nodes from what I can see.
You need support you have many red indices and many unassigned shards...
I see "node left" so perhaps this is a Node Issue..
This is definitely not good...
"allocate_explanation": "cannot allocate because a previous copy of the primary shard existed but can no longer be found on the nodes in the cluster",
Do you have snapshots?
Support will be your best bet did you open a Sev 1 ... You should
I would also going into Snapshot Lifecycle Management.... And make sure you are keeping snapshots as you may need to restore
Also it looks like that you have set many your indices to 0 replicas which means that you are risk of data loss. If your data is important you should always have a replica... That is the best practice.
Thank you for your support. I opened a ticket and the Elastic support were very helpful, and directed me on how to close the red indicies and then restore these from the latest backup.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.


{kind=link}