Hi,
we run 4 elk nodes in cluter using jre 1.8.0.77,logstash 2.3.2,elasticsearch 2.3.2 ,kibana 4.5.1.and there are totally about more than three hundred client server transfering linux log,windows event log and iis log to ELK cluster.
the following is our architecture and H/W configuration:
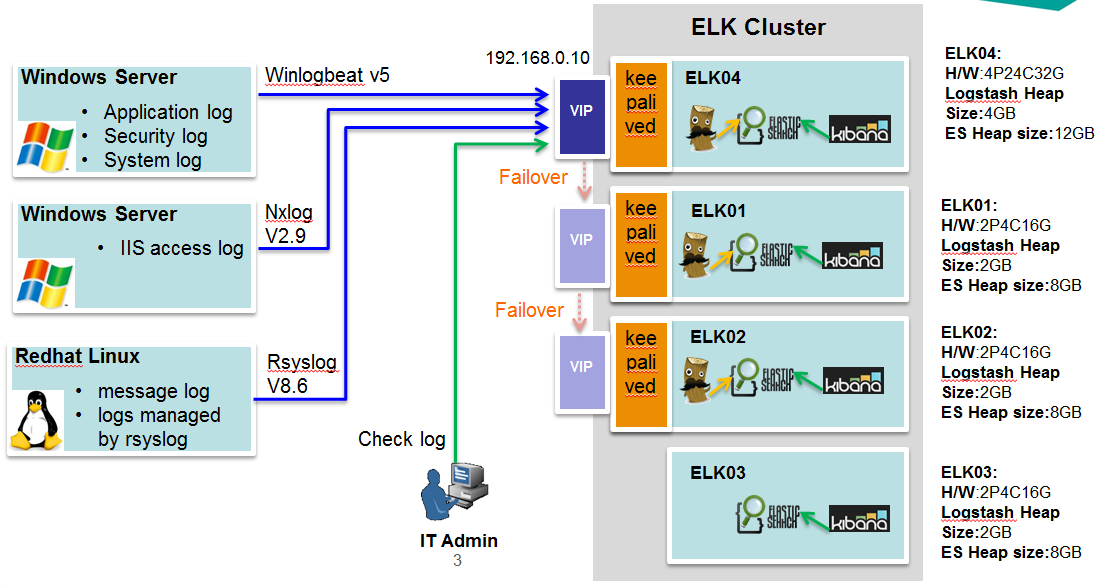
but now we encoutered a critial error, logstash on ELK01 host is receiving and processing logs from client servers. every few days,the elasticsearch.log will log "OutOfMemory" exception,and quit from cluster,at the same time, I can not login OS through ssh remotely,so I have to force to reboot OS.
Could anybody help to fix it? thanks.
[2016-07-25 01:22:35,370][WARN ][index.engine ] [elk04] [it_p5sfcs_iislog-2016.07.24][0] failed engine [refresh failed]
java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Unknown Source)
at org.apache.lucene.index.ConcurrentMergeScheduler.merge(ConcurrentMergeScheduler.java:517)
at org.apache.lucene.index.IndexWriter.maybeMerge(IndexWriter.java:1931)
at org.apache.lucene.index.IndexWriter.getReader(IndexWriter.java:455)
at org.apache.lucene.index.StandardDirectoryReader.doOpenFromWriter(StandardDirectoryReader.java:286)
at org.apache.lucene.index.StandardDirectoryReader.doOpenIfChanged(StandardDirectoryReader.java:261)
at org.apache.lucene.index.StandardDirectoryReader.doOpenIfChanged(StandardDirectoryReader.java:251)
at org.apache.lucene.index.FilterDirectoryReader.doOpenIfChanged(FilterDirectoryReader.java:104)
at org.apache.lucene.index.DirectoryReader.openIfChanged(DirectoryReader.java:137)
at org.apache.lucene.search.SearcherManager.refreshIfNeeded(SearcherManager.java:154)
at org.apache.lucene.search.SearcherManager.refreshIfNeeded(SearcherManager.java:58)
at org.apache.lucene.search.ReferenceManager.doMaybeRefresh(ReferenceManager.java:176)
at org.apache.lucene.search.ReferenceManager.maybeRefreshBlocking(ReferenceManager.java:253)
at org.elasticsearch.index.engine.InternalEngine.refresh(InternalEngine.java:672)
at org.elasticsearch.index.shard.IndexShard.refresh(IndexShard.java:661)
at org.elasticsearch.index.shard.IndexShard$EngineRefresher$1.run(IndexShard.java:1349)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
