Hi all,
Elastic invo:
version[5.6.4], pid[1], build[8bbedf5/2017-10-31T18:55:38.105Z], OS[Linux/4.4.0-11
2-generic/amd64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/1.8.0_151/25.151-b12]
JVM arguments
-Xms5235M, -Xmx5235M, -Des.path.home=/usr/share/elasticsearch
I have a problem with elasticsearch cluster master nodes.
Currently the cluster is running 6x data nodes 3x master and 2x search. Master nodes are on 7.5GB VMs with only Elastic java process running on them. Cluster state size on disk is 22mb. As for data - mostly logs. Only bunch of templates, rather small. Each data node holds approx 600gigs.
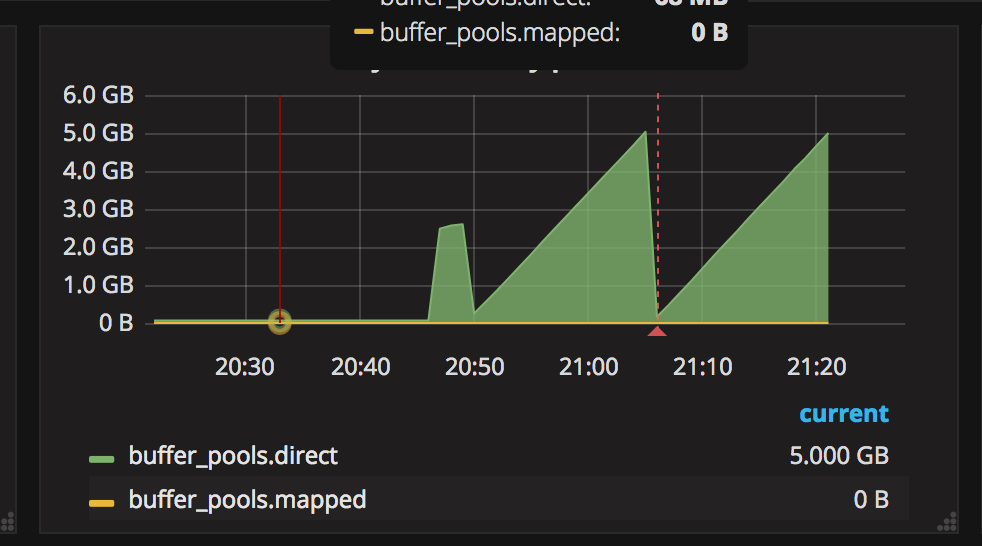
Master nodes are occasionally running out of memory. That seemed strange for me because at the moment when master ran out of memory its heap space was only 30% full. What I noticed is big amount of "Direct buffer pools". At the moment the memory exhaustion happened there were 319 buffer pools which were 5gigabytes in size.
Heap usage when box ran out of mem (21:20)

Direct buffer pools when box ran out of mem (21:20)
As a result the process RSS size was way above 90% of available memory and it started a long (few minutes long) running GC and the new master was elected.
To remedy the memory issues I set:
-Djdk.nio.maxCachedBufferSize=262144 -XX:MaxDirectMemorySize=1500M
This has fixed the problem of memory shortages but now the old gen gc is happening pretty often (every ~4-5 minutes) and the heap never really goes beyond 20%. The buffer pools are cleaned when old gen gc runs so I guess that the GC is itself triggered by the fact that direct memory size went above XX:MaxDirectMemorySize. I am not sure if specifically old gen gc is cleaning direct buffer pools but on the charts I can clearly see that the size of direct buffer pools goes down whenever gc happens:
Each annotation is old gen gc, the chart represents buffer pools.

So now the direct buffer pools are raising at the rate of about ~250-300mb per minute which is pretty big and they trigger GC every few minutes. Is that OK? Why does the direct buffer pools increase in size so quickly on master nodes?
Best regards,
Krzysztof!
