Apologies, there are a massive amount of logs to sort through.
cluster.routing.allocation.node_concurrent_recoveries: "8" = cluster state related timeouts
cluster.routing.allocation.node_concurrent_recoveries: "4" = cluster state related timeouts
cluster.routing.allocation.node_concurrent_recoveries: "2" = cluster state related timeouts
cluster.routing.allocation.node_concurrent_recoveries: "1" = no timeouts
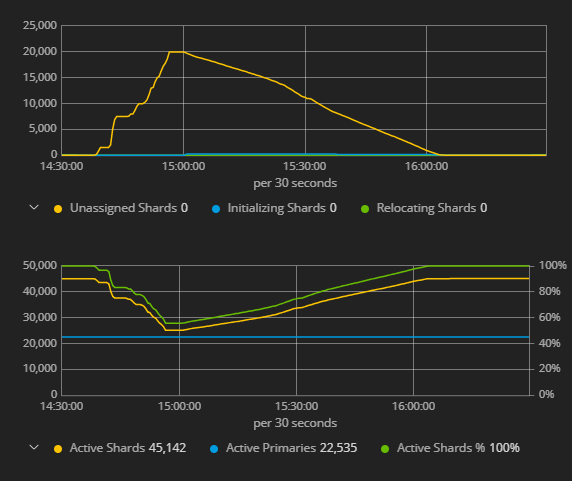
The issue that is hard to understand is that the cold SATA nodes is initializing shards --> which in turn causes Logstash to cease all indexing to the hot SSD nodes because it the put-mapping to the cluster state times out. This invariably ties the indexing on the hot nodes to the performance/availability of the cold nodes?
Enabling shard allocation
[2019-05-01T14:59:49,848][INFO ][o.e.c.s.ClusterSettings ] [esmstr-es-01] updating [cluster.routing.allocation.enable] from [new_primaries] to [all]
There are a bunch of these errors:
[2019-05-01T15:01:19,733][DEBUG][o.e.a.a.i.t.p.TransportPutIndexTemplateAction] [esmstr-es-01] failed to put template [kibana_index_template:.kibana]
org.elasticsearch.cluster.metadata.ProcessClusterEventTimeoutException: failed to process cluster event (create-index-template [kibana_index_template:.kibana], cause [api]) within 30s
at org.elasticsearch.cluster.service.MasterService$Batcher.lambda$onTimeout$0(MasterService.java:127) ~[elasticsearch-6.7.1.jar:6.7.1]
at java.util.ArrayList.forEach(ArrayList.java:1257) ~[?:1.8.0_201]
at org.elasticsearch.cluster.service.MasterService$Batcher.lambda$onTimeout$1(MasterService.java:126) ~[elasticsearch-6.7.1.jar:6.7.1]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:681) [elasticsearch-6.7.1.jar:6.7.1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_201]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_201]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_201]
[2019-05-01T15:01:23,620][DEBUG][o.e.a.a.i.t.p.TransportPutIndexTemplateAction] [esmstr-es-01] failed to put template [kibana_index_template:.kibana]
org.elasticsearch.cluster.metadata.ProcessClusterEventTimeoutException: failed to process cluster event (create-index-template [kibana_index_template:.kibana], cause [api]) within 30s
at org.elasticsearch.cluster.service.MasterService$Batcher.lambda$onTimeout$0(MasterService.java:127) ~[elasticsearch-6.7.1.jar:6.7.1]
at java.util.ArrayList.forEach(ArrayList.java:1257) ~[?:1.8.0_201]
at org.elasticsearch.cluster.service.MasterService$Batcher.lambda$onTimeout$1(MasterService.java:126) ~[elasticsearch-6.7.1.jar:6.7.1]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:681) [elasticsearch-6.7.1.jar:6.7.1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_201]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_201]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_201]
And a bunch of these errors:
[2019-05-01T15:01:26,060][WARN ][o.e.d.z.PublishClusterStateAction] [esmstr-es-01] timed out waiting for all nodes to process published state [983329] (timeout [30s], pending nodes: [{esdata-es-01}{ceLamsouQEqybbA-VxHiXg}{AlkIyh0VRCmrDgn3qkflmQ}{x.x.x.x}{x.x.x.x:9200}{evenodd=odd, xpack.installed=true, chassis=chassis153, tier=sata}])
And the error that matches with the Logstash error from above. There are tens of thousands of these errors that run all the way from 15:05 through to 16:05:
[2019-05-01T15:06:41,823][DEBUG][o.e.a.a.i.m.p.TransportPutMappingAction] [esmstr-es-01] failed to put mappings on indices [[[winlogbeat-2019.05.01/QZyYVT30Se63Edfp13WAbQ]]], type [doc]
org.elasticsearch.cluster.metadata.ProcessClusterEventTimeoutException: failed to process cluster event (put-mapping) within 30s
at org.elasticsearch.cluster.service.MasterService$Batcher.lambda$onTimeout$0(MasterService.java:127) ~[elasticsearch-6.7.1.jar:6.7.1]
at java.util.ArrayList.forEach(ArrayList.java:1257) ~[?:1.8.0_201]
at org.elasticsearch.cluster.service.MasterService$Batcher.lambda$onTimeout$1(MasterService.java:126) ~[elasticsearch-6.7.1.jar:6.7.1]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:681) [elasticsearch-6.7.1.jar:6.7.1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_201]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_201]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_201]