This crash happened again. This time I had Marvel / Kibana setup, so I have detailed logging. Some of the charts are below, but I converted the output to a PDF showing all events.
It's difficult to really understand what is happening. The charts show that right before the crash, memory increased a bit, and the JVM spent most of its time trying to garbage collect. This increased the load. The machine became relatively unresponsive.
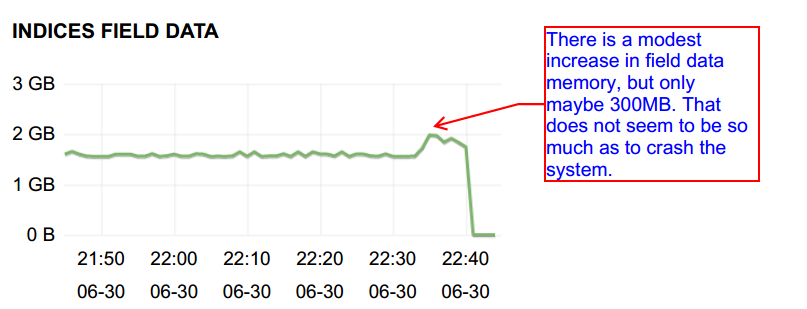
The only culprit seems to be field data, which increased right before the crash:
But this increase seems relatively modest, a few hundred MB at most. It seems unclear why this would take down the entire node. Also, this memory only really increased at around 22:34, whereas the instability started a few minutes earlier. So this increased field data may be an effect of the error, not a cause of it.
This seems like an important issue because the instability of a single machine is affecting the stability of an entire cluster. This is because the node did not crash, but became relatively unresponsive. The master kicked the node out of the cluster, and then added it back again and again. The subsequent intense relocating made the entire cluster unresponsive. This breaks Elasticsearch's high availability assurances.
And for the sake of completeness, here are the log output right at the crash time of 22:33
[2016-07-01 02:33:09,415][INFO ][monitor.jvm ] [elasticsearch1-elasticsearch-3-vm] [gc][young][272253][28134] duration [881ms], collections [1]/[1.7s], total [881ms]/[2.5h], memory [23.6gb]->[23.9gb]/[29.9gb], all_pools {[young] [77.6mb]->[8.9mb]/[532.5mb]}{[survivor] [66.5mb]->[66.5mb]/[66.5mb]}{[old] [23.4gb]->[23.8gb]/[29.3gb]}
[2016-07-01 02:33:10,584][WARN ][monitor.jvm ] [elasticsearch1-elasticsearch-3-vm] [gc][young][272254][28135] duration [1s], collections [1]/[1.1s], total [1s]/[2.5h], memory [23.9gb]->[24.4gb]/[29.9gb], all_pools {[young] [8.9mb]->[6.8mb]/[532.5mb]}{[survivor] [66.5mb]->[66.5mb]/[66.5mb]}{[old] [23.8gb]->[24.4gb]/[29.3gb]}
[2016-07-01 02:33:27,199][WARN ][monitor.jvm ] [elasticsearch1-elasticsearch-3-vm] [gc][young][272270][28138] duration [1s], collections [1]/[1.2s], total [1s]/[2.5h], memory [25gb]->[25.5gb]/[29.9gb], all_pools {[young] [21.4mb]->[50.2mb]/[532.5mb]}{[survivor] [66.5mb]->[66.5mb]/[66.5mb]}{[old] [24.9gb]->[25.4gb]/[29.3gb]}
[2016-07-01 02:33:33,712][INFO ][monitor.jvm ] [elasticsearch1-elasticsearch-3-vm] [gc][young][272276][28139] duration [822ms], collections [1]/[1.5s], total [822ms]/[2.5h], memory [25.9gb]->[26gb]/[29.9gb], all_pools {[young] [453.5mb]->[161.4mb]/[532.5mb]}{[survivor] [66.5mb]->[66.5mb]/[66.5mb]}{[old] [25.4gb]->[25.8gb]/[29.3gb]}
[2016-07-01 02:33:34,958][WARN ][monitor.jvm ] [elasticsearch1-elasticsearch-3-vm] [gc][young][272277][28140] duration [1s], collections [1]/[1.2s], total [1s]/[2.5h], memory [26gb]->[26.4gb]/[29.9gb], all_pools {[young] [161.4mb]->[18.9mb]/[532.5mb]}{[survivor] [66.5mb]->[66.5mb]/[66.5mb]}{[old] [25.8gb]->[26.3gb]/[29.3gb]}
[2016-07-01 02:33:36,210][INFO ][monitor.jvm ] [elasticsearch1-elasticsearch-3-vm] [gc][young][272278][28141] duration [940ms], collections [1]/[1.2s], total [940ms]/[2.5h], memory [26.4gb]->[26.8gb]/[29.9gb], all_pools {[young] [18.9mb]->[48.9mb]/[532.5mb]}{[survivor] [66.5mb]->[66.5mb]/[66.5mb]}{[old] [26.3gb]->[26.7gb]/[29.3gb]}
[2016-07-01 02:33:44,758][INFO ][monitor.jvm ] [elasticsearch1-elasticsearch-3-vm] [gc][young][272286][28143] duration [888ms], collections [1]/[1.5s], total [888ms]/[2.5h], memory [27gb]->[27.4gb]/[29.9gb], all_pools {[young] [63.1mb]->[3.1mb]/[532.5mb]}{[survivor] [66.5mb]->[66.5mb]/[66.5mb]}{[old] [26.8gb]->[27.3gb]/[29.3gb]}
[2016-07-01 02:33:46,338][INFO ][monitor.jvm ] [elasticsearch1-elasticsearch-3-vm] [gc][young][272287][28144] duration [790ms], collections [1]/[1.5s], total [790ms]/[2.5h], memory [27.4gb]->[27.9gb]/[29.9gb], all_pools {[young] [3.1mb]->[98.9mb]/[532.5mb]}{[survivor] [66.5mb]->[66.5mb]/[66.5mb]}{[old] [27.3gb]->[27.8gb]/[29.3gb]}
[2016-07-01 02:33:47,538][WARN ][monitor.jvm ] [elasticsearch1-elasticsearch-3-vm] [gc][young][272288][28145] duration [1s], collections [1]/[1.2s], total [1s]/[2.5h], memory [27.9gb]->[28.3gb]/[29.9gb], all_pools {[young] [98.9mb]->[3.7mb]/[532.5mb]}{[survivor] [66.5mb]->[66.5mb]/[66.5mb]}{[old] [27.8gb]->[28.3gb]/[29.3gb]}
Any other insights or recommendations into this issue?