Hi Lior,
I think you misunderstood the setting David is talking about.
He's talking about total_shards_per_node index setting.
Not the cluster setting.
The cluster setting is to set the max shard count per node irrespective of the index the shard is part of.
The index setting, the one he was talking about is to control the max count of shards from the same index that can be on a node. Which can be used to prevent too many shards from the same index... today's index... from being on the same node.
To clarify further and discuss this further, let's clarify what you mean by an active shard, I'll give a definition and you can give yours if it's different.
An active shard is a shard of an index currently being indexed into. All shards of an index currently being indexed into are equally active shards. With daily indices, all shards of all indices for today's date are active. This is obviously indexing centric, because I think this is what you were talking about.
Now because you didn't share a proper output of
GET /_cat/indices?v&s=index
It's hard to give specific advice and see if David suggestion will be able to really prevent "unequally hot nodes" problem in your setup. Please share this info.
In the mean time I'll share how I alleviate this in my cluster and hopefully it helps and we can discuss how/if you do something similar after you've shared your "cat indices".
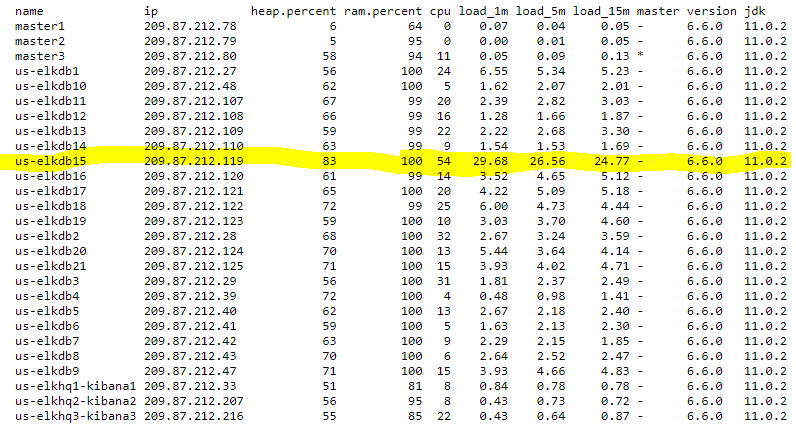
I have 20 data nodes, all same hardware. I want the indexing workload to be spread very equally as this is a log/metric cluster. If indexed into shards are not spread VERY equally on my 20 nodes I have a problem with some (or one) nodes becoming more busy than other nodes and that doesn't work well as my cluster have periods during the day where it runs pretty hot across the board. If it gets unbalanced in terms of hot shards, the nodes that work more than the other simply have too much work and they can't keep up.
What I do is that all my indices which receive (or can sometime receive) significant event/sec rate are configured to have a shard count which is a multiple of my node count. So 20,40,60, etc
For example my metricbeat index has 10 shards with 1 replica, so 20 shards. All my big indices in terms of indexing workload have a minimum of 20 shards.
20/20=1 If I can make sure that each node host 1 and only 1 of these, the workload is equally spread. The idea is that the workload has to be equally divisible or else it just can't be equally distributed. I could have 20 shards and 1 replica, so 40/20=2 and that would work too.
In that context (10 shards, 1rep = 20 shards) If I was using the setting suggested by David, maybe I would set it to:
index.routing.allocation.total_shards_per_node: 1
Which means each nodes can't have more than 1 of those 20. They all have 1, the workload is spread equally, profit.
There would be downsides if I did that though so maybe I would have to set it higher... Because if you set that to 1 in that context and you loose nodes, the setting could prevent the cluster from compensating for the lost nodes. The index could stay yellow or red until the nodes comes back, which can be pretty bad depending on how long you can have nodes missing.
For now at least, I elected to use other settings:
cluster.routing.allocation.balance.shard
cluster.routing.allocation.balance.index
cluster.routing.allocation.balance.threshold
https://www.elastic.co/guide/en/elasticsearch/reference/current/shards-allocation.html#_shard_balancing_heuristics
By putting a huge portion of the weight on the balance.index the cluster wants to spread the shards from the same index equally across the nodes. So for 20 shards and 20 nodes, it puts 1 on each node.
I'm telling the cluster to prefer balancing the shards from each index equally across the nodes vs preferring to balance the total shard count across the nodes irrespective of which index they are from. But none of that is specific to currently indexed into indices or shards. It does that for all indices, not just today's indices... But as long as it applies to today's indices, I get what I want. The fact that older indices are also flattened/spread equally as possible across the nodes, doesn't have downsides that I have identified so far. On the contrary, it also spreads the search load more equally across the nodes.
The downside I have identified and that I currently live with, is that my currently active indices are sometimes oversharded or undersharded according to the normal best practice of "in your usecase each shard should have a size of around x GBs each. I either use 20,40,60,etc so I can't at the same time, yield shards that are also perfectly targeting the specific size they should have.
My future will be a bit brighter I think. With ILM I plan to be able to abandon strictly time based rotation in favor of time and size based rotation. This will mean less over/under sharded indices.
Also with ILM I will be able to more easily shrink oversharded indices once they are no longer being indexed into. If only indexed into indices are oversharded, it means I have a LOT less over sharded indices all together.
Guys from Elastic might recommend against my method here, so stay careful and you can wait to get more feedback before trying to implement any of that. I certainly don't claim ES guru level.
But the only thing I have currently being able to implement to spread my load and prevent super hot nodes, is to use a shard count which is a multiple of my node count for all indexing heavy indices + the settings I mentionned above. If I used less than a multiple of node count, hotter nodes would be possible and so it would happen.
If I had 60 nodes, it would be a lot crazier to have all my big indices with a minimum of 60 shards. I would have to use:
https://www.elastic.co/guide/en/elasticsearch/reference/current/shard-allocation-filtering.html
To put specific indices on specific groups of nodes and then I would do "index shard count is a multiple of the node count for the node group where this index is going". I could then control the node count that shard count needs to be a multiple of.
Interesting subject BTW, thanks for bringing it up!



 )
)