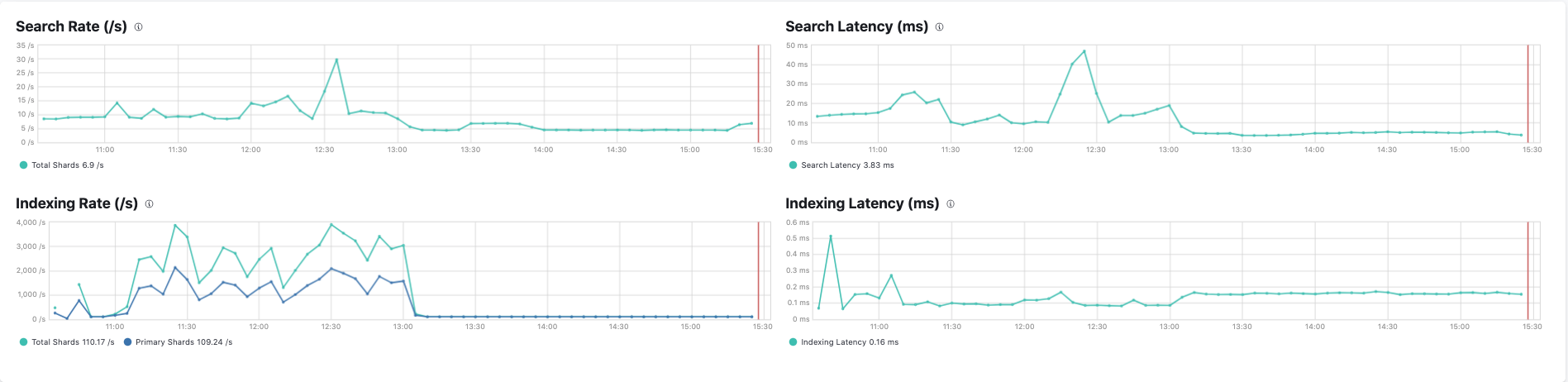
I'm currently using the enrich processors to enrich my data coming in. It's been working great however more recently when I increase the indexing rate, I start to get the below error:
[16:47:15] [ELASTIC] Row Error { type: 'es_rejected_execution_exception', reason: 'Could not perform enrichment, enrich coordination queue at capacity [1024/1024]' }
This is concerning because it seems like we're starting to lose data when we do that and we can't have that happen.
How can we best deal with this? Our cluster is a index heavy cluster with every document needing a lookup. We're getting to about 4k-6k events/s with no problem but beyond that we get this error. I don't see any documentation about this. Should we increase the queue capacity somehow? What kind of steps can we take?