Carelessly make several primary shards lost and now the elasticsearch state is below:
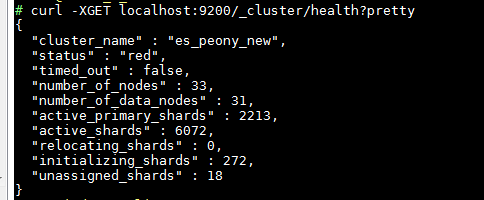
it takes about 2 days that hundreds of shards in initializing
how to make health green
version is 1.3.1
Wait.
Then upgrade to 1.7 at least, preferably 2.X.
i have waited for about 3 days , is there some solutions to make it green as soon as possible
Delete the indices?
If i delete them, how about my data, will it all disappear?
Yes. That's why you need to wait.
But i find it that there some shards jump from initializing to unassigned more times, what's the terminal I should wait for,
How is your cluster set up? How many master eligible nodes do you have? What is minimum_master_nodes set to? What is the specification of the hosts?
Elasticsearch 1.3.1 is quite old and is missing enhancements related to cluster management that came in later 1.x versions. As you are running a reasonably large cluster I agree with @warkolm that you should upgrade to at least 1.7.
One important change in 2.x that could benefit you due to the size of the cluster is the ability for Elasticsearch to send cluster state diffs. This is considerably more efficient for larger clusters that replicating the entire cluster state to all nodes on every change, which is what was done prior to 2.x.