Hi,
I have one cluster with 3 Node (1800 Indices, 7892 Share, 113M doc and 61GB data) Load balance
ES-01, ES-02(master), ES-03.
i using model :
Client -> LS Forwarder (LS-FW-01, LS-FW02) -> MS queue -> LS Indexer (LS-01, LS-02) -> ES (ES-01, ES-02, Es-03).
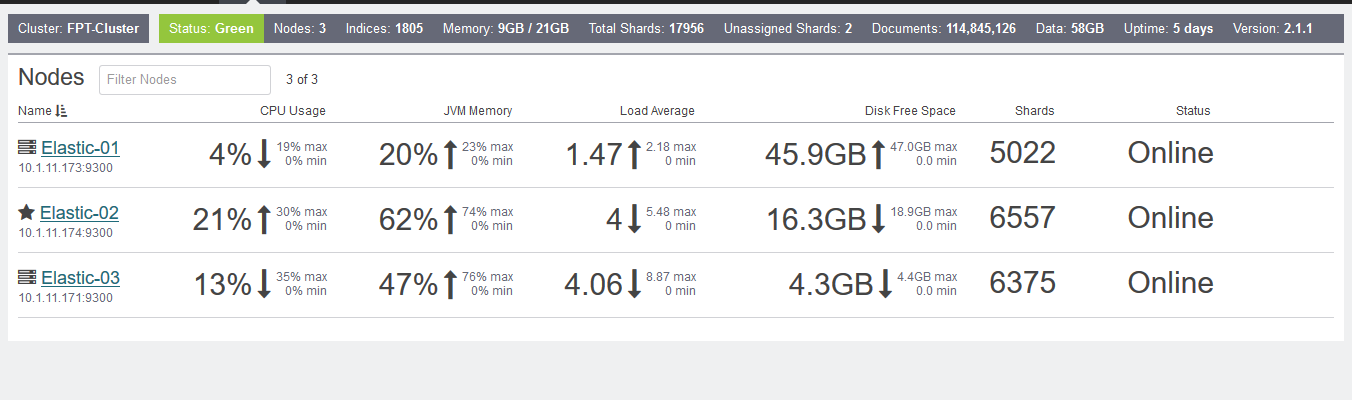
After restart Es-01, Disk on ES-01 ~ 32GB, ES-02 ~ 28GB, ES-03 ~31GB
When i restart ES-01, and all shard located success (Cluste Health Green).
Disk on ES-01 ~47GB, ES-02 ~19GB, ES-03 - 5GB ???
And i view indices on kopf plugin and see ...
http://upsieutoc.com/images/2015/12/30/error-located.png
On Marvel
And check log on ES-01
[2015-12-30 22:09:52,879][DEBUG][action.admin.indices.stats] [Elastic-03] [indices:monitor/stats] failed to execute operation for shard [[winlogbeat-mb-02-2015.10.26][0], node[THvwaUErSyaNlblCpUDgLQ], relocating [lGQsv8jKQUWQ8gUnlCjKxQ], [P], v[4], s[RELOCATING], a[id=6PP8PSgORNCasIezP9q-2A, rId=eC4gMfdTRRChcccx1LFN8g], expected_shard_size[20921]]
[winlogbeat-mb-02-2015.10.26][[winlogbeat-mb-02-2015.10.26][0]] BroadcastShardOperationFailedException[operation indices:monitor/stats failed]; nested: ShardNotFoundException[no such shard];
at org.elasticsearch.action.support.broadcast.node.TransportBroadcastByNodeAction$BroadcastByNodeTransportRequestHandler.onShardOperation(TransportBroadcastByNodeAction.java:405)
at org.elasticsearch.action.support.broadcast.node.TransportBroadcastByNodeAction$BroadcastByNodeTransportRequestHandler.messageReceived(TransportBroadcastByNodeAction.java:382)
at org.elasticsearch.action.support.broadcast.node.TransportBroadcastByNodeAction$BroadcastByNodeTransportRequestHandler.messageReceived(TransportBroadcastByNodeAction.java:371)
at org.elasticsearch.shield.transport.ShieldServerTransportService$ProfileSecuredRequestHandler.messageReceived(ShieldServerTransportService.java:165)
at org.elasticsearch.transport.netty.MessageChannelHandler$RequestHandler.doRun(MessageChannelHandler.java:299)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: [winlogbeat-mb-02-2015.10.26][[winlogbeat-mb-02-2015.10.26][0]] ShardNotFoundException[no such shard]
at org.elasticsearch.index.IndexService.shardSafe(IndexService.java:198)
at org.elasticsearch.action.admin.indices.stats.TransportIndicesStatsAction.shardOperation(TransportIndicesStatsAction.java:98)
at org.elasticsearch.action.admin.indices.stats.TransportIndicesStatsAction.shardOperation(TransportIndicesStatsAction.java:47)
at org.elasticsearch.action.support.broadcast.node.TransportBroadcastByNodeAction$BroadcastByNodeTransportRequestHandler.onShardOperation(TransportBroadcastByNodeAction.java:401)
... 8 more
####What happen ?
####And one question.
I Using 1 Message Queue and 2 Logstash Indexer (Ls-01, LS-02). In two config file LS-01, LS-02
input {
rabbitmq {
host => "10.1.11.177"
queue => "logstash-queue"
#durable => true
key => "logstash-key"
exchange => "logstash-rabbitmq"
threads => 6
exclusive => false
prefetch_count => 512
port => 5677
user => "administrator"
password => "password"
}
}
So, in this case, data is duplicate . LS-01, LS-02 got same log together???
####Question about name indices
i have 10 server , which i need get log. I using filebeat.
So should be I set name inde on configfile is "filbeat-server1", "filebeat-server2" ..... "filebeat-server10". Or should be I set name index in all config file is "filebeat" ?
Now i using case 1 , set indexname "filebeat-server-1, 2,3,4,5...." but when run i have many many Idices.Do Cluster having multiple tables affect performance???
Thanks