I've been having a big issue with my elastic stack, I am sending information from sql server to elasticsearch using logstash, and each index for each table gets created with the table columns as mappings in the index in elasticsearch, but for some reason at a certain point all the fields get mixed and shown the same for all indeces, why is this happening? I've tried removing all indeces and creating them again from scratch and everything is fine, but after a few days the same thing happens, all fields from every table are put together and show in all indices. What can I do to prevent this, and show only what I need for each index?
When you create multiple configuration files in Logstash these are by default concatenated into a single config file if you do not explicitly specify them as separate pipelines. Unless you are protecting different pieces of logic with conditionals this means that data from all inputs will go to all outputs.
Thank you for your response and guidance, I have done what you suggested, and I still get all the fields in all of my indeces, here is an example of a logstash conf file:
input {
jdbc {
jdbc_driver_library => "/home/*****/elastic/mssql-jdbc-12.8.1.jre11.jar"
jdbc_driver_class => "com.microsoft.sqlserver.jdbc.SQLServerDriver"
jdbc_connection_string => ""
jdbc_user => ""
jdbc_password => ""
schedule => "* * * * *"
statement => "SELECT TOP (1000) ISNULL(nec_id,0) nec_id,
ISNULL(nec_valorHB,'') nec_valorHB,
ISNULL(nec_etiquetaHB,'') nec_etiquetaHB,
ISNULL(nec_etiquetaPD,'') nec_etiquetaPD,
ISNULL(nec_necesidad,'') nec_necesidad,
ISNULL(nec_idnecesidad,0) nec_idnecesidad,
ISNULL(nec_estatus,'') nec_estatus,
ISNULL(nec_ids,0) nec_ids,
ISNULL(nec_idsubtipo,0) nec_idsubtipo
FROM Cat_necesidad WHERE nec_id > :sql_last_value ORDER BY nec_id"
use_column_value => true
tracking_column => "nec_id"
tracking_column_type => "numeric"
last_run_metadata_path => "/home/****/elastic/lastrun/Central_Cat_necesidad_lastrun.log"
}
}
filter {
# Optional transformations go here
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "central_cat_necesidad"
document_id => "%{nec_id}"
}
stdout { codec => json_lines } # This will output data to the console for debugging
}
Here is the example of my pipeline.yml file:
- pipeline.id: agenda_rol_cita_logstash.conf
path.config: "/etc/logstash/conf.d/agenda_rol_cita_logstash.conf"
- pipeline.id: central_agenda_logstash.conf
path.config: "/etc/logstash/conf.d/central_agenda_logstash.conf"
- pipeline.id: central_cat_necesidad_logstash.conf
path.config: "/etc/logstash/conf.d/central_cat_necesidad_logstash.conf"
- pipeline.id: central_cat_partos_logstash.conf
path.config: "/etc/logstash/conf.d/central_cat_partos_logstash.conf"
- pipeline.id: central_cat_relacion_logstash.conf
path.config: "/etc/logstash/conf.d/central_cat_relacion_logstash.conf"
- pipeline.id: central_cat_tratamiento_logstash.conf
path.config: "/etc/logstash/conf.d/central_cat_tratamiento_logstash.conf"
- pipeline.id: central_lead_logstash.conf
path.config: "/etc/logstash/conf.d/central_lead_logstash.conf"
- pipeline.id: central_leadbasico_logstash.conf
path.config: "/etc/logstash/conf.d/central_leadbasico_logstash.conf"
- pipeline.id: central_paciente_logstash.conf
path.config: "/etc/logstash/conf.d/central_paciente_logstash.conf"
- pipeline.id: central_pacientesocioeconomico_logstash.conf
path.config: "/etc/logstash/conf.d/central_pacientesocioeconomico_logstash.conf"
- pipeline.id: central_scorescalculos_logstash.conf
path.config: "/etc/logstash/conf.d/central_scorescalculos_logstash.conf"
Here is an example of the same fields in different indices
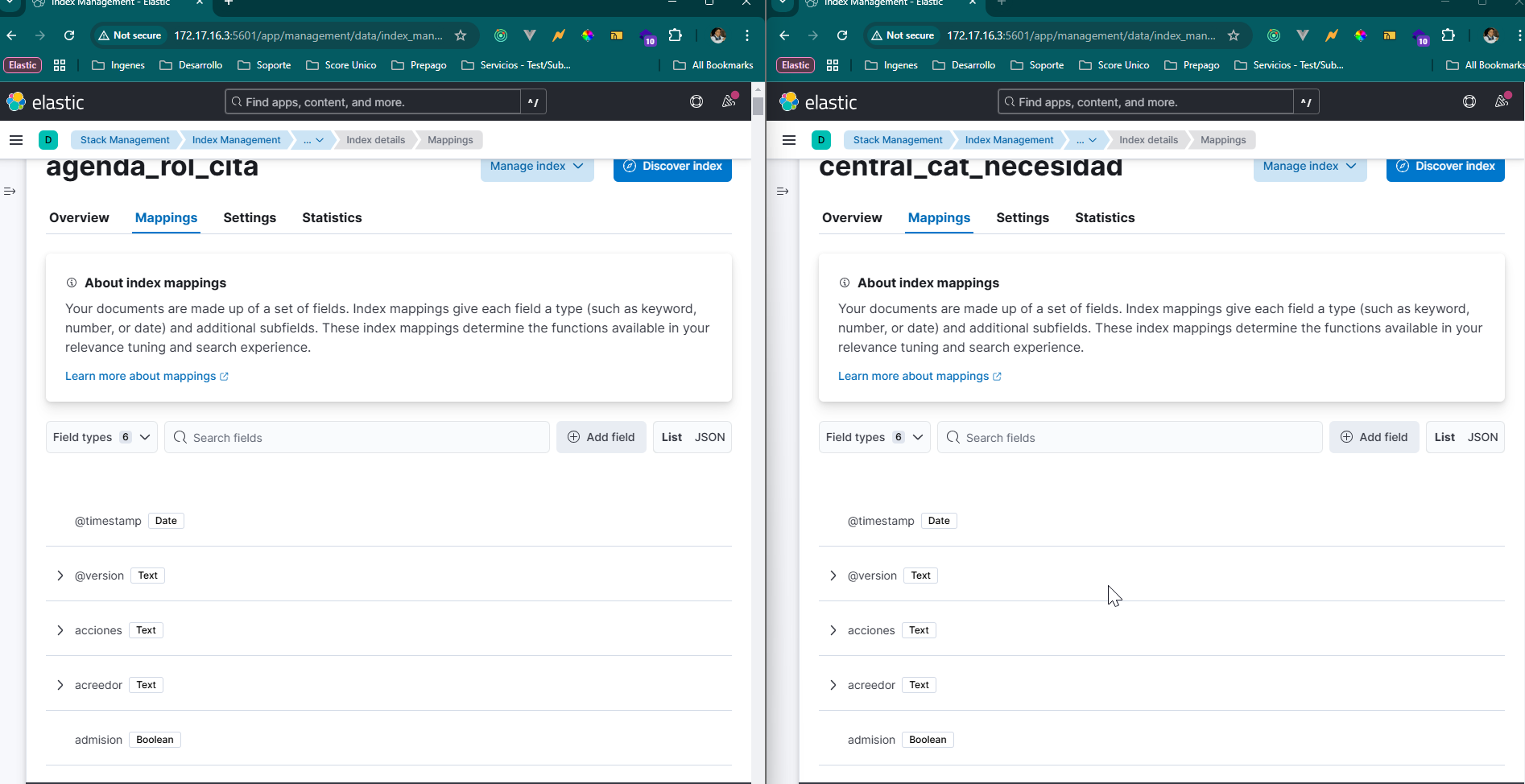
I am still missing something? What else can I try?
Did you delete the old indices before you started Logstash with the new pipeline config so indices and mappings were generated based on the new data?
yes I did
How are you starting and running Logstash? Does it even take the pipelines file into account?
What happens if you move the config files to a different directory which is not the one Logstash by default reads config from?