Hi there,
I am running two nodes (elastic1, elastic2) on top of Mesos and Docker.
The following is a short description of the cluster setup:
Both nodes are running the official elasticsearch docker image version 2.3.5. Both nodes have the same Docker (1.11.2) and Mesos (0.28.1) version.
The main difference among the node is the hardware:
elastic1: 2 magnetic disks (RIDE 0), 64GB RAM, AMD Opteron 6338P
elastic2: 2 SSD disks (RIDE 0), 128GB RAM, Intel Xeon E5-1650V2
Since elastic 1 uses magnetic disks it has an additional es setting:
index.merge.scheduler.max_thread_count: 1
On both nodes memory swapping is disabled via the es setting: bootstrap.mlockall: true
The issue is a bit complex to describe but basically when the node elastic2 acts as master it enters in a loop where it will use up all assigned memory (5GB) and than garbage collect all of it (takes about 10sec) to start over again. However if the node elastic2 is acting as slave everything runs smoothly. Attached you will find an image showing some metrics of the before and after master role assignment. The red line on the image indicates the exact time when roles are switch between the nodes.
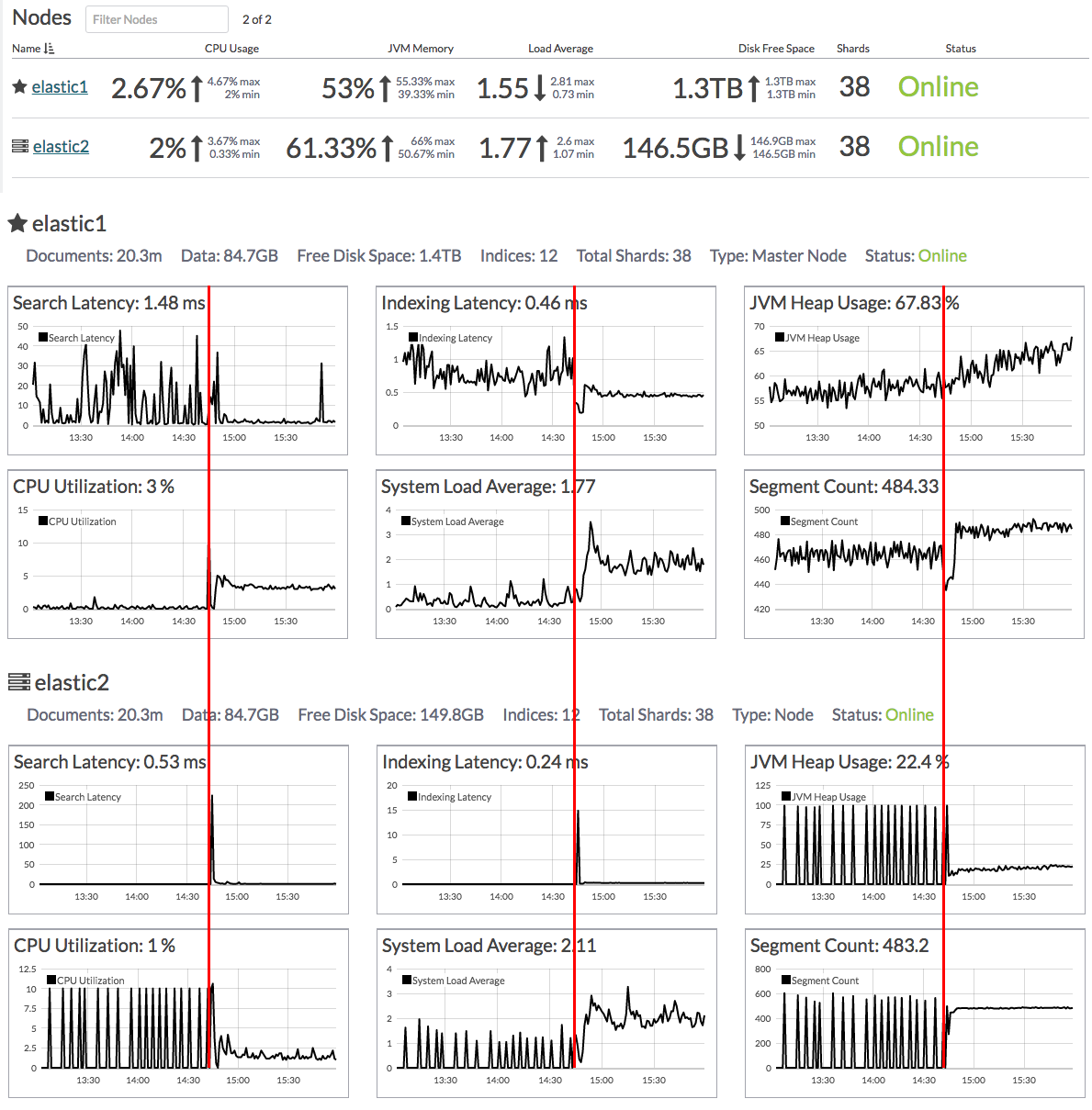
Also I will attach the log file showing the before and after entries. You can see the many GC runs and the time it takes. After the restart and the role switch no more entries were logged and the cluster was stable.
Any idea what could cause such a strange behavior? Why would the node elastic2 stop working if the role is master and why is the issue not affecting the node elastic1?
Logs:
[2016-08-22 12:44:23,487][WARN ][monitor.jvm ] [elastic2] [gc][old][57324][19436] duration [12.9s], collections [1]/[13.5s], total [12.9s]/[2.6d], memory [4.7gb]->[4.8gb]/[4.9gb], all_pools {[young] [653.2mb]->[636.9mb]/[665.6mb]}{[survivor] [0b]->[0b]/[83.1mb]}{[old] [4.1gb]->[4.1gb]/[4.1gb]}
[2016-08-22 12:44:34,708][WARN ][monitor.jvm ] [elastic2] [gc][old][57325][19437] duration [11s], collections [1]/[10.6s], total [11s]/[2.6d], memory [4.8gb]->[4.7gb]/[4.9gb], all_pools {[young] [636.9mb]->[596.3mb]/[665.6mb]}{[survivor] [0b]->[0b]/[83.1mb]}{[old] [4.1gb]->[4.1gb]/[4.1gb]}
[2016-08-22 12:44:49,023][WARN ][monitor.jvm ] [elastic2] [gc][old][57326][19438] duration [14.1s], collections [1]/[14.8s], total [14.1s]/[2.6d], memory [4.7gb]->[4.7gb]/[4.9gb], all_pools {[young] [596.3mb]->[588mb]/[665.6mb]}{[survivor] [0b]->[0b]/[83.1mb]}{[old] [4.1gb]->[4.1gb]/[4.1gb]}
Received killTask
Shutting down
================ MASTER SWITCH ================
[2016-08-22 12:44:58,478][INFO ][node ] [elastic2] version[2.3.5], pid[1], build[90f439f/2016-07-27T10:36:52Z]
[2016-08-22 12:44:58,478][INFO ][node ] [elastic2] initializing ...
[2016-08-22 12:44:58,825][INFO ][plugins ] [elastic2] modules [reindex, lang-expression, lang-groovy], plugins [license, marvel-agent], sites
[2016-08-22 12:44:58,842][INFO ][env ] [elastic2] using [1] data paths, mounts [[/usr/share/elasticsearch/data (/dev/sda3)]], net usable_space [149.3gb], net total_space [434.5gb], spins? [possibly], types [ext4]
[2016-08-22 12:44:58,842][INFO ][env ] [elastic2] heap size [4.9gb], compressed ordinary object pointers [true]
[2016-08-22 12:44:59,955][INFO ][node ] [elastic2] initialized
[2016-08-22 12:44:59,955][INFO ][node ] [elastic2] starting ...
[2016-08-22 12:45:00,043][INFO ][transport ] [elastic2] publish_address {xx.xx.xx.xx:9300}, bound_addresses {[::]:9300}
[2016-08-22 12:45:00,046][INFO ][discovery ] [elastic2] newsriver/-JAQ76_VT3iWrWvYlre-rA
[2016-08-22 12:45:03,103][INFO ][cluster.service ] [elastic2] detected_master {elastic1}{8iaBxIvQQn2JM7tNFMjaYg}{xx.xx.xx.xx}{xx.xx.xx.xx:9300}{master=true}, added {{elastic1}{8iaBxIvQQn2JM7tNFMjaYg}{xx.xx.xx.xx}{xx.xx.xx.xx:9300}{master=true},}, reason: zen-disco-receive(from master [{elastic1}{8iaBxIvQQn2JM7tNFMjaYg}{xx.xx.xx.xx}{xx.xx.xx.xx:9300}{master=true}])
[2016-08-22 12:45:03,182][INFO ][http ] [elastic2] publish_address {xx.xx.xx.xx:9200}, bound_addresses {[::]:9200}
[2016-08-22 12:45:03,182][INFO ][node ] [elastic2] started
Details:
Elasticsearch version: 2.3.5
Plugins installed: [license,marvel-agent]
JVM version:
openjdk version "1.8.0_102"
OpenJDK Runtime Environment (build 1.8.0_102-8u102-b14.1-1~bpo8+1-b14)
OpenJDK 64-Bit Server VM (build 25.102-b14, mixed mode)
OS version: Official Docker ES Image 2.3.5