Hi all,
this is a follow-up to the following issue we posted earlier last month: What could make a healthy ES5.3.1 cluster go OOM & unresponsive INSTANTLY?
Setup:
- Production cluster with 3 pretty large nodes (8Cores/30GiB)
- Mixed (but pretty consistent) workload of ingest and classic site search with lots of filters, aggregations, etc.
- Cluster idles around between 5-20% CPU - 99.9% of the time
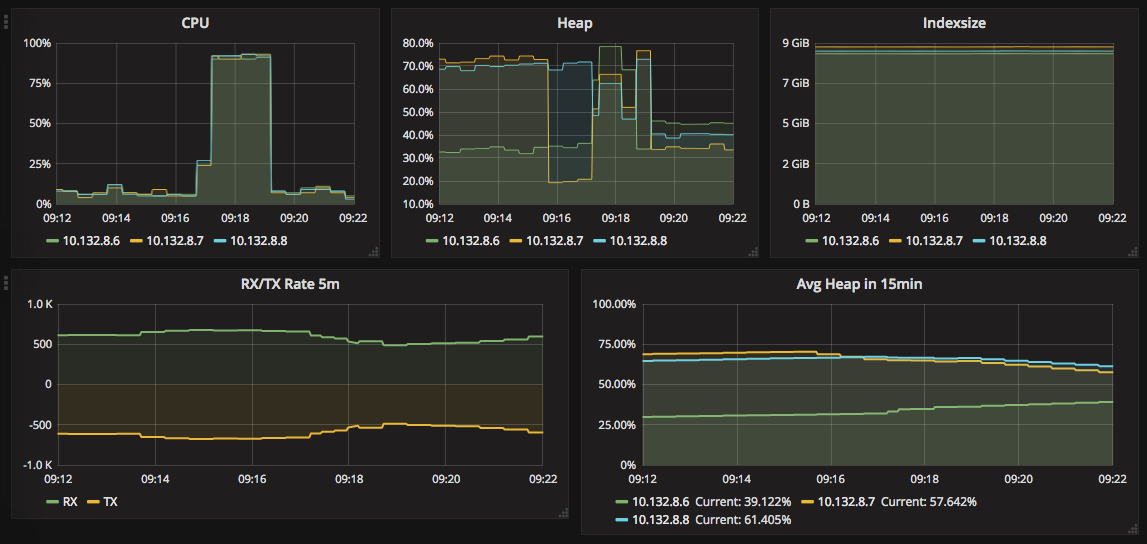
- Around 1-2 times per day, the cluster goes completely unresponsive with 100% CPU (mostly Garbage Collecting) for just a few minutes
- After that, the cluster goes back to normal, queues are emptied and everything is fine.
- In contrast to the issue referenced above (with more background info inside), the cluster doesn't completely crash anymore, just stall.
What we tried / what it's not:
- There is no change in quantity or quality of queries during these incidents: We went so far to mirror our production load from the load balancer to the API served by Elastic and ran it again against the cluster: nothing happened.
- We set all query timeouts for read accesses to 5s and in normal operation, there are virtually no queries running longer than 2s
- We set all circuit breakers to 1% and they still never trip
- It's not hardware or noisy neighbors: We're on GCP and rotated the cluster multiple times, even to different machine types in different AZs
- It's not plugins. The only ones we have are backup repositories and the times don't correlate.
- It's not ingest related: We regenerated all of our ES documents in a short amount of time and didn't hit the incident.
- We double / triple checked JVM settings and it's the recommended vanilla production config by ES
- Downsizing the cluster seemed to increase the events: Half the size lead to about double the amount of these incidents which points to something resource related
- Out of other sensible ideas, we set up a script to monitor the hot threads every minute, but we didn't find any obvious smoking gun. It just looked busy on the same mix of queries that we have all the time (with the cluster happily crunching through them), but they were simply queued up due to X.
We just don't know what X is.
HELP! 
Attached are screenshots from such an incident - we also have the hot threads export, but it doesn't fit in here (120kB) and attaching txt files isn't allowed.