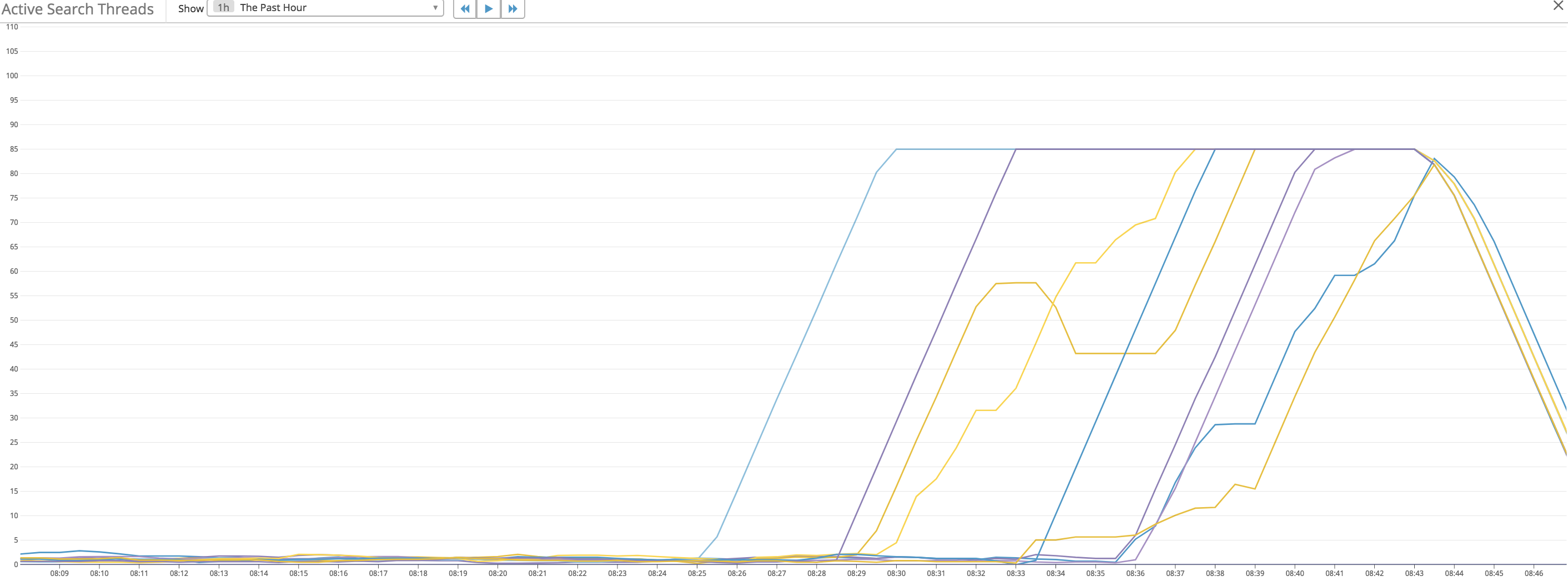
We recently upgrade a 5.6 cluster to 6.3.1 and started having issues with high heap utilization correlated with Active Search Thread Queue exhaustion/locking/blocking. We are logging queries from kibana and the client side app (still using the 5.6 transport client), but nothing seems to be out of the ordinary. During this state, indexing drops to nothing, all API's except for the health api (which returns green) do not respond. After time (about 30 mins), the cluster updates with the first node with the locked active search as unavailable and the cluster begins to go into yellow/degraded health.
The quickest way for us to remediate the issue is to perform a restart of the ES processes.
The following are the cluster information:
Version: 6.3.1
OS: CentOS 6.10
JDK: jdk1.8.0_102_x64
Data Nodes: 10 x 15GB Heap
Master Nodes: 3 x 4GB Heap
Cliennt Nodes: 3 x 2GB Heap
Primary Store Size: ~1TB
Shards: 30 x 3 Replicas
X-Pack: Default Open-Source, with monitoring enabled
Other configuration items: Default
Index Rate is fairly low, about ~500 doc/second.
Heap Utilization spike during Active Search Threads:
We just had this issue occur again today with the same behavior in the screenshots above. I was able to get thread dumps from one of the blocked nodes, and this was one of the thread output.
"elasticsearch[host28][search][T#1]" #281 daemon prio=5 os_prio=0 tid=0x00007f6070012800 nid=0xba30 waiting for monitor entry [0x00007f5eb42d1000]
java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.logging.log4j.core.appender.OutputStreamManager.writeBytes(OutputStreamManager.java:360)
- waiting to lock <0x00000004fe2860c8> (a org.apache.logging.log4j.core.appender.OutputStreamManager)
at org.apache.logging.log4j.core.layout.TextEncoderHelper.writeEncodedText(TextEncoderHelper.java:96)
at org.apache.logging.log4j.core.layout.TextEncoderHelper.encodeText(TextEncoderHelper.java:65)
at org.apache.logging.log4j.core.layout.StringBuilderEncoder.encode(StringBuilderEncoder.java:68)
at org.apache.logging.log4j.core.layout.StringBuilderEncoder.encode(StringBuilderEncoder.java:32)
at org.apache.logging.log4j.core.layout.PatternLayout.encode(PatternLayout.java:219)
at org.apache.logging.log4j.core.layout.PatternLayout.encode(PatternLayout.java:57)
at org.apache.logging.log4j.core.appender.AbstractOutputStreamAppender.directEncodeEvent(AbstractOutputStreamAppender.java:177)
at org.apache.logging.log4j.core.appender.AbstractOutputStreamAppender.tryAppend(AbstractOutputStreamAppender.java:170)
at org.apache.logging.log4j.core.appender.AbstractOutputStreamAppender.append(AbstractOutputStreamAppender.java:161)
at org.apache.logging.log4j.core.config.AppenderControl.tryCallAppender(AppenderControl.java:156)
at org.apache.logging.log4j.core.config.AppenderControl.callAppender0(AppenderControl.java:129)
at org.apache.logging.log4j.core.config.AppenderControl.callAppenderPreventRecursion(AppenderControl.java:120)
at org.apache.logging.log4j.core.config.AppenderControl.callAppender(AppenderControl.java:84)
at org.apache.logging.log4j.core.config.LoggerConfig.callAppenders(LoggerConfig.java:448)
at org.apache.logging.log4j.core.config.LoggerConfig.processLogEvent(LoggerConfig.java:433)
at org.apache.logging.log4j.core.config.LoggerConfig.log(LoggerConfig.java:417)
at org.apache.logging.log4j.core.config.LoggerConfig.log(LoggerConfig.java:403)
at org.apache.logging.log4j.core.config.AwaitCompletionReliabilityStrategy.log(AwaitCompletionReliabilityStrategy.java:63)
at org.apache.logging.log4j.core.Logger.logMessage(Logger.java:146)
at org.apache.logging.log4j.spi.ExtendedLoggerWrapper.logMessage(ExtendedLoggerWrapper.java:217)
at org.elasticsearch.common.logging.PrefixLogger.logMessage(PrefixLogger.java:103)
at org.apache.logging.log4j.spi.AbstractLogger.tryLogMessage(AbstractLogger.java:2116)
at org.apache.logging.log4j.spi.AbstractLogger.logMessageSafely(AbstractLogger.java:2100)
at org.apache.logging.log4j.spi.AbstractLogger.logMessage(AbstractLogger.java:1994)
at org.apache.logging.log4j.spi.AbstractLogger.logIfEnabled(AbstractLogger.java:1966)
at org.apache.logging.log4j.spi.AbstractLogger.debug(AbstractLogger.java:317)
at org.elasticsearch.xpack.security.authz.accesscontrol.OptOutQueryCache.doCache(OptOutQueryCache.java:56)
at org.apache.lucene.search.IndexSearcher.createWeight(IndexSearcher.java:738)
at org.apache.lucene.search.BooleanWeight.<init>(BooleanWeight.java:54)
at org.apache.lucene.search.BooleanQuery.createWeight(BooleanQuery.java:207)
at org.apache.lucene.search.IndexSearcher.createWeight(IndexSearcher.java:736)
at org.apache.lucene.search.IndexSearcher.createNormalizedWeight(IndexSearcher.java:726)
at org.elasticsearch.search.internal.ContextIndexSearcher.createNormalizedWeight(ContextIndexSearcher.java:125)
at org.apache.lucene.search.IndexSearcher.search(IndexSearcher.java:462)
at org.elasticsearch.search.query.QueryPhase.execute(QueryPhase.java:266)
at org.elasticsearch.search.query.QueryPhase.execute(QueryPhase.java:107)
at org.elasticsearch.indices.IndicesService.lambda$loadIntoContext$14(IndicesService.java:1134)
at org.elasticsearch.indices.IndicesService$$Lambda$3036/594545152.accept(Unknown Source)
at org.elasticsearch.indices.IndicesService.lambda$cacheShardLevelResult$15(IndicesService.java:1187)
at org.elasticsearch.indices.IndicesService$$Lambda$3037/1216434388.get(Unknown Source)
at org.elasticsearch.indices.IndicesRequestCache$Loader.load(IndicesRequestCache.java:160)
at org.elasticsearch.indices.IndicesRequestCache$Loader.load(IndicesRequestCache.java:143)
at org.elasticsearch.common.cache.Cache.computeIfAbsent(Cache.java:399)
at org.elasticsearch.indices.IndicesRequestCache.getOrCompute(IndicesRequestCache.java:116)
at org.elasticsearch.indices.IndicesService.cacheShardLevelResult(IndicesService.java:1193)
at org.elasticsearch.indices.IndicesService.loadIntoContext(IndicesService.java:1133)
at org.elasticsearch.search.SearchService.loadOrExecuteQueryPhase(SearchService.java:322)
at org.elasticsearch.search.SearchService.executeQueryPhase(SearchService.java:357)
at org.elasticsearch.search.SearchService$2.onResponse(SearchService.java:333)
at org.elasticsearch.search.SearchService$2.onResponse(SearchService.java:329)
at org.elasticsearch.search.SearchService$3.doRun(SearchService.java:1019)
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:725)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at org.elasticsearch.common.util.concurrent.TimedRunnable.doRun(TimedRunnable.java:41)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Locked ownable synchronizers:
- <0x000000050562ff78> (a java.util.concurrent.ThreadPoolExecutor$Worker)
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.