hey folks,
as we added an additional es node yesterday(actually an other instance of
ES with an different data path on our server), some of the shards that were
moved to this node, keep stuck initializing.
Given to the debug logs, it seems like they got corrupted during the copy
process (about 20 of 140 moved shards got this problem...) so i decided it
could help to manually assign them to an node, using the reroute-api.
https://lh6.googleusercontent.com/-qSB3BJT-F5o/VIqjbiphLTI/AAAAAAAAAC4/9Yno_hajBgM/s1600/es.PNG
https://lh5.googleusercontent.com/-ijpXObA2tms/VIqkw9lfDHI/AAAAAAAAADY/Gc3sK_NE0do/s1600/size.PNG
{kind=link}
{kind=link}
=> curl -X POST \
'http://localhost:9200/_cluster/reroute?pretty=true' \
-d '{ "commands" : [ { "allocate" : { "index" : "logstash-2014.06.07",
"shard" : 2 , "node" : "Storage", "allow_primary" : 2 }}]}'
After I issued the command, ES tried to initialize the shard, but then this
suddenly happend:
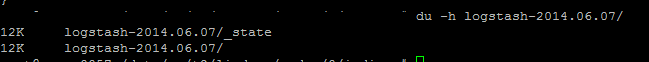{kind=link}
It seems like ES decided to delete the whole shard, due to its (potential)
corruption and with it 1/3 of the data in it.
In my opinion ES should never ever be allowed to delete anything without
permission, any clue what happened in this case?
Thanks for feedback
--
You received this message because you are subscribed to the Google Groups "elasticsearch" group.
To unsubscribe from this group and stop receiving emails from it, send an email to elasticsearch+unsubscribe@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/elasticsearch/b737268a-32aa-4100-ba03-ac3b12e616fd%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.