I'm working on a use where we need to copy messages from 2 Kafka topics to Elasticsearch, in order to search and visualize data in Web App.
I have setup Elastic Cloud on Kubernetes with Elasticsearch and Kibana, and performed quick PoC by using ordinary index without aliases and ILM.
Now I want to take the PoC further and create production ready Elastic stack and since Im working with time series data, I thought Data Streams would be a good fit for my use case.
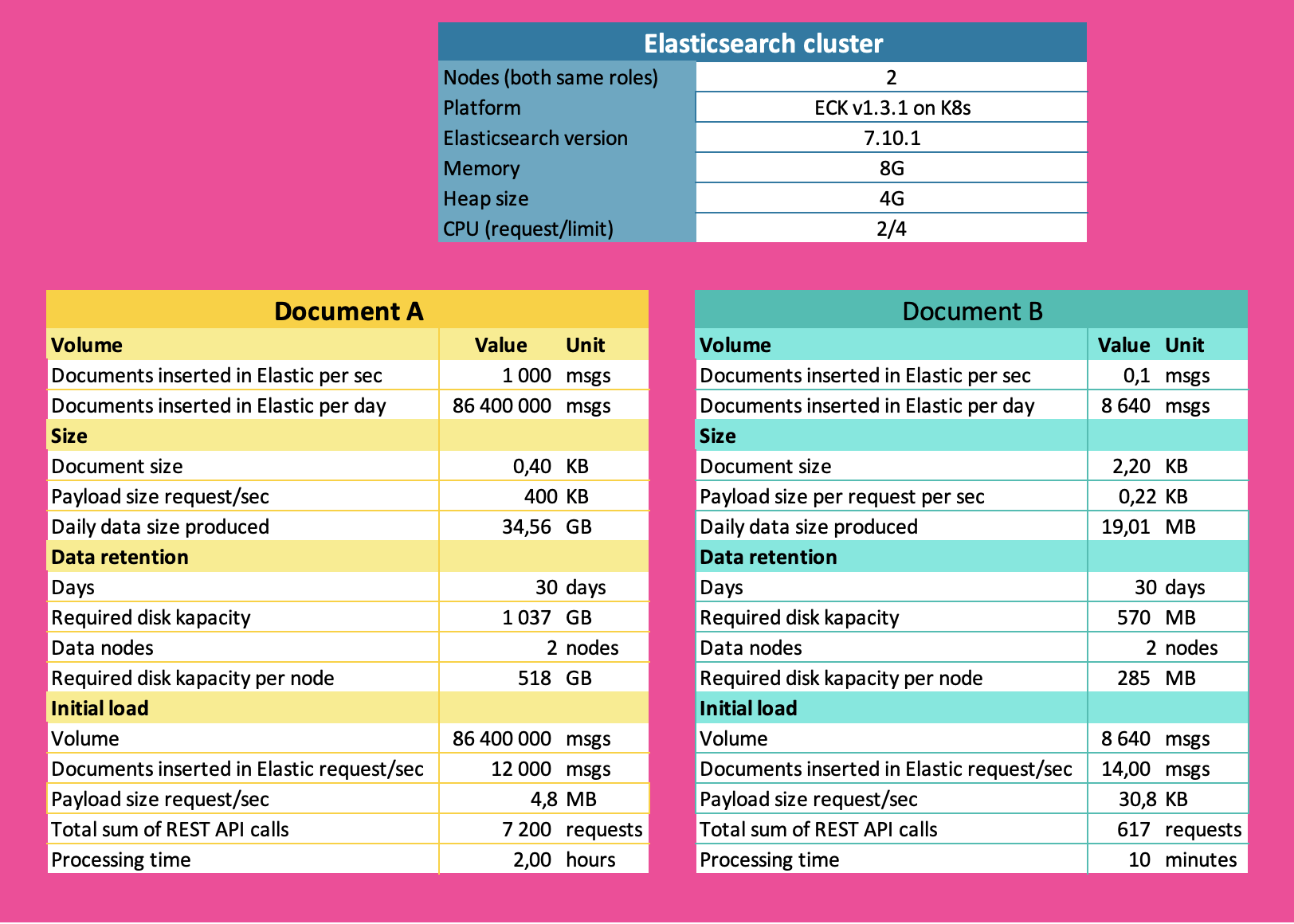
I have created an overview of my current cluster setup and characteristics for Document A and B in diagram below. Document B contains GPS position + some metadata for an vehicle at given point of time, Document A contains trip data for vehicle and will be used in search field. When trip is selected map is visualizing all GPS positions for vehicle by retrieving all related Document B (based on a ref value).
I would like feedback on following questions:
- Since charasteristics and payload of Document A and B are different Im thinking on separating those on two different Data Streams/Indices. I guess you agree?
- How many shards should I have for Data Streams for Document A and B?
- Given data retention for last 30 days, should I have rollover pattern per day (one index per day) for both Data Stream or use different approach for each one?
- Any input on other cluster related settings are also welcome!
The Web app will be used by limited amount of users (2-5 users). Replication is set to 0 since we can afford loosing data if one Node gets broken.