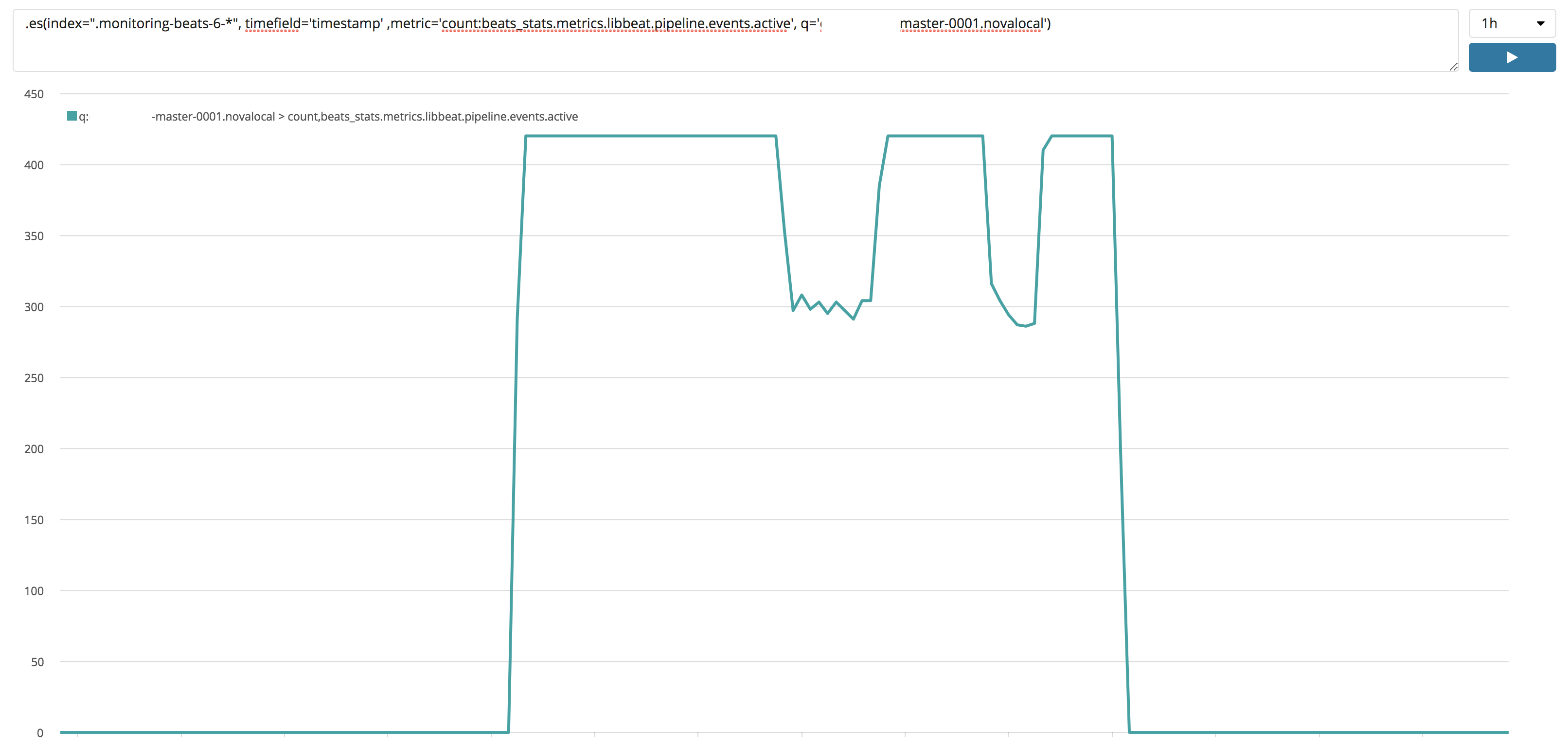
Hi, running 6.4.2
I see this in my /var/log/messages
Nov 11 18:49:37 xxxxxx-0002 systemd: filebeat.service: main process exited, code=exited, status=2/INVALIDARGUMENT
Nov 11 18:49:37 xxxxxx-0002 systemd: Unit filebeat.service entered failed state.
Nov 11 18:49:37 xxxxxx-0002 systemd: filebeat.service failed.
Nov 11 18:49:38 xxxxxx-0002 systemd: filebeat.service holdoff time over, scheduling restart.
Nov 11 18:50:20 xxxxxx-0002 kernel: [21658] 0 21658 3747640 3650216 7166 1 0 filebeat
Nov 11 18:50:20 xxxxxx-0002 kernel: [21658] 0 21658 3747640 3651148 7168 28 0 filebeat
Nov 11 18:50:20 xxxxxx-0002 kernel: [21658] 0 21658 3747640 3654834 7175 28 0 filebeat
Nov 11 18:50:20 xxxxxx-0002 kernel: [21658] 0 21658 3747640 3655690 7177 28 0 filebeat
Nov 11 18:50:20 xxxxxx-0002 kernel: [21658] 0 21658 3747640 3655685 7177 33 0 filebeat
Nov 11 18:55:40 xxxxxx-0002 kernel: [21658] 0 21658 3976276 3849259 7623 18036 0 filebeat
Nov 11 18:55:47 xxxxxx-0002 kernel: [21658] 0 21658 3976276 3849256 7623 18039 0 filebeat
Nov 11 18:55:47 xxxxxx-0002 kernel: [21658] 0 21658 3976276 3849230 7623 18065 0 filebeat
Nov 11 18:55:54 xxxxxx-0002 kernel: [21658] 0 21658 3976276 3849072 7623 18223 0 filebeat
Nov 11 18:55:54 xxxxxx-0002 kernel: [21658] 0 21658 3976276 3849063 7623 18232 0 filebeat
Nov 11 19:03:57 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3744999 7637 45191 0 filebeat
Nov 11 19:10:58 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3646305 7636 50770 0 filebeat
Nov 11 19:13:22 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3645069 7637 55020 0 filebeat
Nov 11 19:13:27 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3645049 7637 55040 0 filebeat
Nov 11 19:17:12 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641613 7637 58522 0 filebeat
Nov 11 19:17:12 xxxxxx-0002 kernel: filebeat invoked oom-killer: gfp_mask=0x201da, order=0, oom_score_adj=0
Nov 11 19:17:12 xxxxxx-0002 kernel: filebeat cpuset=/ mems_allowed=0
Nov 11 19:17:12 xxxxxx-0002 kernel: CPU: 0 PID: 21665 Comm: filebeat Kdump: loaded Tainted: G W ------------ 3.10.0-862.3.2.el7.x86_64 #1
Nov 11 19:17:12 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641509 7637 58626 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641509 7637 58626 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641509 7637 58626 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641485 7637 58650 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641485 7637 58650 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641485 7637 58650 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641485 7637 58650 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: filebeat invoked oom-killer: gfp_mask=0x201da, order=0, oom_score_adj=0
Nov 11 19:17:13 xxxxxx-0002 kernel: filebeat cpuset=/ mems_allowed=0
Nov 11 19:17:13 xxxxxx-0002 kernel: CPU: 0 PID: 21659 Comm: filebeat Kdump: loaded Tainted: G W ------------ 3.10.0-862.3.2.el7.x86_64 #1
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641466 7637 58669 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641455 7637 58680 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641410 7637 58725 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641405 7637 58730 0 filebeat
Nov 11 19:17:13 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641391 7637 58744 0 filebeat
Nov 11 19:17:14 xxxxxx-0002 kernel: [21658] 0 21658 4002812 3641330 7637 58805 0 filebeat
And here is the last metrics:
2018-11-11T19:19:08.202Z INFO [monitoring] log/log.go:141 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":41380,"time":{"ms":5}},"total":{"ticks":110240,"time":{"ms":21},"value":110240},"user":{"ticks":68860,"time":{"ms":16}}},"info":{"ephemeral_id":"07c894b6-6a13-47ef-a2af-7e3eae818b0e","uptime":{"ms":1770040}},"memstats":{"gc_next":163008880,"memory_alloc":152316592,"memory_total":49717784168,"rss":245760}},"filebeat":{"events":{"added":10,"done":10},"harvester":{"open_files":1,"running":1}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":10,"batches":1,"total":10}},"outputs":{"kafka":{"bytes_read":400,"bytes_write":5129}},"pipeline":{"clients":2,"events":{"active":0,"published":10,"total":10},"queue":{"acked":10}}},"registrar":{"states":{"current":1,"update":10},"writes":{"success":1,"total":1}},"system":{"load":{"1":17.53,"15":49.7,"5":53.97,"norm":{"1":4.3825,"15":12.425,"5":13.4925}}}}}} 2018-11-11T19:19:38.201Z INFO [monitoring] log/log.go:141 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":41400,"time":{"ms":17}},"total":{"ticks":110320,"time":{"ms":79},"value":110320},"user":{"ticks":68920,"time":{"ms":62}}},"info":{"ephemeral_id":"07c894b6-6a13-47ef-a2af-7e3eae818b0e","uptime":{"ms":1800040}},"memstats":{"gc_next":162984672,"memory_alloc":103258432,"memory_total":49746718000}},"filebeat":{"events":{"added":37,"done":37},"harvester":{"open_files":1,"running":1}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":37,"batches":4,"total":37}},"outputs":{"kafka":{"bytes_read":1348,"bytes_write":16129}},"pipeline":{"clients":2,"events":{"active":0,"published":37,"total":37},"queue":{"acked":37}}},"registrar":{"states":{"current":1,"update":37},"writes":{"success":4,"total":4}},"system":{"load":{"1":10.85,"15":48.14,"5":48.87,"norm":{"1":2.7125,"15":12.035,"5":12.2175}}}}}}