Noticed that Filebeat on one of our servers in ECE goes bananas. Where as other vms with same config, same settings and same roles sends about 1000 logs per 15 minutes this server sends roughly 500k in same time period. It also seems alot of those logs are old ones.

Is that server on the beta1 or the beta2 release of ECE? I believe one of the improvements in beta2 is that Filebeat is more selective about what gets sent.
I relayed your question to the developer who worked on this part of ECE.
Nik
Hello, @iremmats!
Echoing @nrichers question, and adding a few more of my own:
-
Is that server on the beta1 or the beta2 release of ECE?
-
On the affected host, are all log files affected, or only some? For example, are you seeing high traffic from only file X, or high traffic from files X, Y, and Z? I'm most interested here in getting a list of the affected files for the high traffic situation.
-
Same as the previous question, but regarding the "a lot of those logs are old ones" instead -- exactly which files are affected by the duplicate sending behavior?
I'll probably have more questions once you get me the answers to these, but this will help us get started.
- The server is Beta2. We ran Beta1 before (on other machines, other network etc) and the difference in how much metrics are gathered from the machines themselves is big. Good work there.

2 and 3. Im attaching some screenshots. They are from one about one hour worth of time. In the last one you can see there is a different time the event is added to Elasticsearch from the actual timestamp of the row.

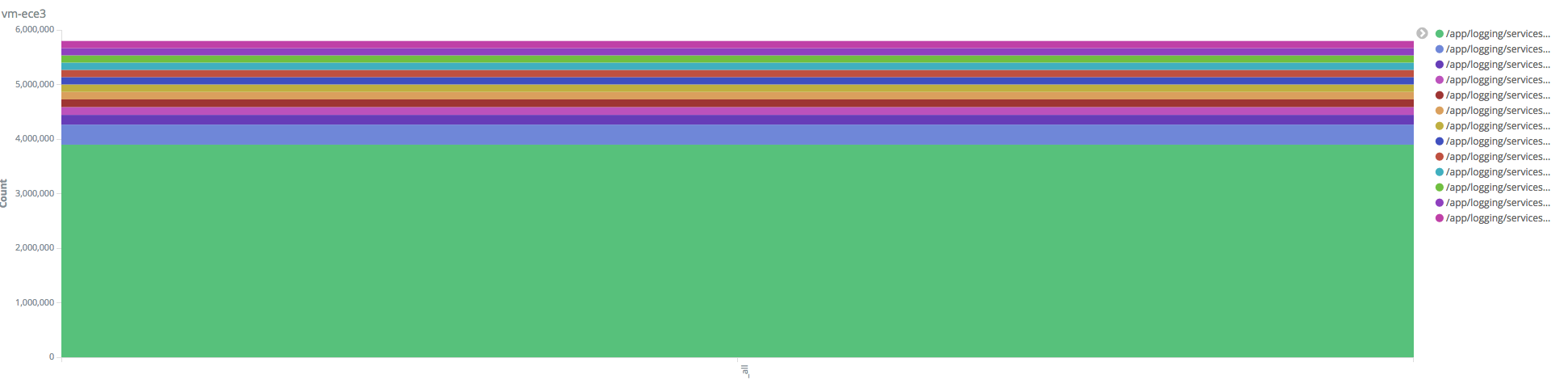

Very interesting -- that information helps a lot. Thanks for sending it.
Can you zip up the filebeat logs and send me a link to them? They're accessible at a path like /mnt/data/elastic/YOUR_RUNNER_NAME_HERE/services/beats-runner/logs/filebeat.log* on the host VM, you don't need to get them out of the beats-runner docker container itself.
Along the same lines, if you could send a few of the beats-runner.log files, as well, that would be very helpful.
Here are all the stuff from that folder. Next time give me a logstash configuration and an Elasticsearch endpoint. Sending text files is so 2005. 

Alright, I've got a potential fix for you, I'd like you to try killing the beats-runner container, it'll restart automatically, and I think when it comes back up the problem will have gone away (if it doesn't, then that will also be highly valuable information):
docker kill frc-beats-runners-beats-runner
Can you run the above command on the affected host and let me know if that solves the problem?
I demoted the server from ECE yesterday (and attached another one) so that command doesn't do anything. 
If if happens again Ill try restarting the docker containers though.
@iremmats Alright, sounds good. Please do reach out if the problem comes up again. And thanks very much for sending us those logs, they were very helpful for us. Cheers!