This is a side-effect of having too many segments on a single node.
This means you need to reduce the number of shards per node (eg. by shrinking some indices) and/or reduce the number of segments per shard (by force-merging some indices, just beware to ONLY do this on READ-ONLY indices).
It means too many segments are open at the same time, it is neither related to indexing or searching. You could close them by I presume you need them for indexing or searching so this is not really an option.
Our cluster has 28 index in 10 datanodes and divide into 400 shard,per index has 500 segments and 100GB docs.Can you give a parameter optimization suggestion for this case? Thank you.
OK, this is consistent with the number of stored fields readers instances in the heap dump. How many processors do you have on each machine? Do you overwrite the size of thread pools or the processors setting?
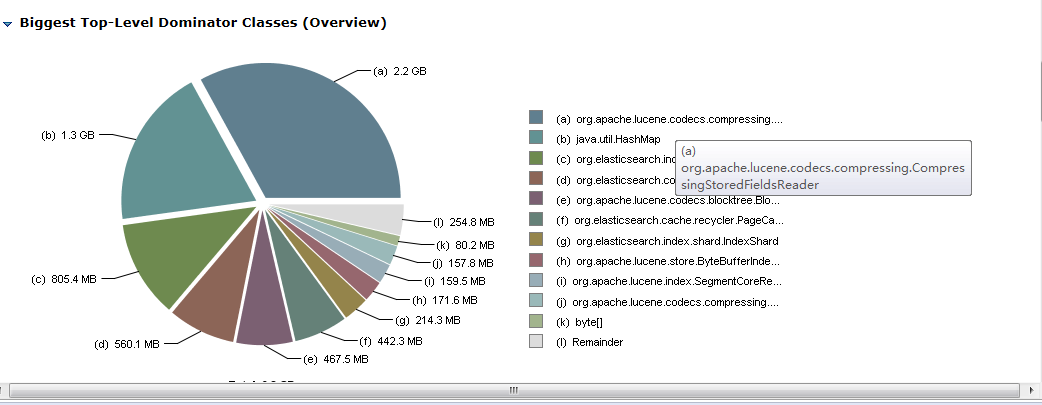
Thank you. Things look sane to me, these 2GB of heap retained by stored fields readers are due to the fact that they keep some state per-thread per-segment. I don't think it makes sense to reduce the number of threads that you have, which is reasonable regarding your number of cores. So I think we should either keep things this way (2GB should not be that much for a beefy machine), or look into reducing the number of segments by force-merging read-only indices if any, or trying to have fewer shards overall in the cluster.
Apache, Apache Lucene, Apache Hadoop, Hadoop, HDFS and the yellow elephant
logo are trademarks of the
Apache Software Foundation
in the United States and/or other countries.