Hi guys,
I am using elasticsearch for a while, but I am newbie on Graph API. I just indexed lastfm data into ES and one sample document in my index as follows:
{
"_index": "lastfm",
"_type": "song",
"_id": "AVg-oFWHtNjcLv7Y8nnT",
"_score": 1,
"_source": {
"timestamp": "2009-02-03T16:54:25Z",
"userid": "user_000001",
"artist-name": "Ken Ishii",
"track-name": "Frame Out",
"musicbrainz-track-id": "8f28cbe6-3e46-4f96-816d-304620f64b41",
"musicbrainz-artist-id": "6d4c4759-8a16-4b9f-83e2-4c225307fc85",
"user": {
"gender": "m",
"signup": "Aug 13, 2006",
"country": "Japan"
}
}
}
What I want to do here is to find relations among artists-artists (I mean people listening some artist, they also listen another artist), among countries-artists, among user-artists and so on.
I can visulize charts on artist name in Kibana in a correct way as follows:

However when I try to find relations on graph api, I find vertexes but I cannot find relations among vertexes and I cannot expand selected vertexes ("artist-name.keyword" field selected)
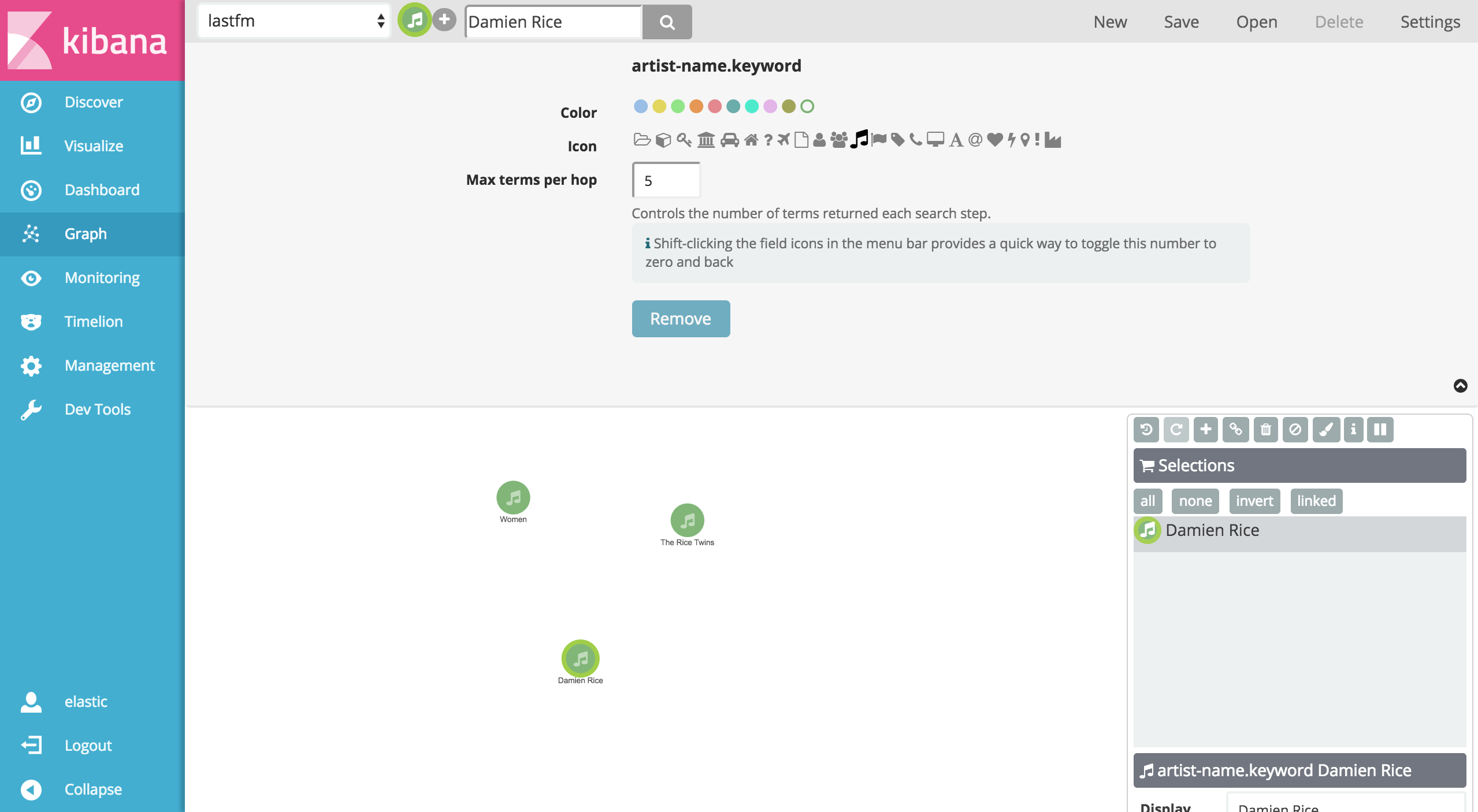
When I select "artist-name" field, it gives me the following error: "Error 400 Bad Request: Fielddata is disabled on text fields by default. Set fielddata=true on [artist-name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory."
It is okay, I managed to solve it with the following:
PUT lastfm/_mapping/song
{
"properties": {
"artist-name": {
"type": "text",
"fielddata": true
}
}
}
Now, I am able to display vertexes and their relations, however "damien" and "rice" are located on different vertexes, they should be on one specific vertex "damien rice"

Any help on this will make me very happy.
Thanks,
 ).
).